Research: My research areas are related to computer vision (CV), deep learning (DL), and machine learning (ML).
Some of the active areas of research include:
Transfer learning (Domain adaptation, Incremental learning).
Fairness and bias-free learning.
Uncertainty in deep learning (Bayesian models).
Data generative models (GANs, VAEs, and Diffusion models).
We are seeking motivated researchers who are passionate about computer vision, machine learning, and deep learning. If you are interested, please send us your CV and highlight your areas of interest and experience to visdomdse@gmail.com.
For more details please visit the Visual Data Computing Group (VisDom) at Dept of DSE, IISER Bhopal.
Reviewer of IEEE Transactions on Multimedia, Pattern Recognition, IEEE Transactions on Neural Networks and Learning Systems, Multimedia Tools and Applications, International Journal of Computer Vision and IEEE Transactions on Image Processing etc.
Teaching
Transfer Learning for Computer Vision (Jan26- May26)
Modern spoken language understanding (SLU) systems are increasingly deployed in real-world settings, where specific functionalities may need to be removed due to policy or safety constraints. In SLU, a functionality corresponds to an intent and its associated slot-generation behavior. However, in autoregressive models, suppressing a target intent does not eliminate the conditional mapping that generates slots conditioned on that intent. When the intent prefix is externally supplied, the model can reconstruct the original intent-slot structure. We identify this structural failure as \textbf{\emph{capability persistence}}. We propose \textit{\underline{B}inding \underline{S}ubspace (BSU)}, a representation-level framework that isolates and attenuates intent-conditioned directions underlying this mapping. Across SLU benchmarks, BSU substantially reduces forced-prefix recoverability while preserving retained performance.
@inproceedings{jangid2026relif3d,
Author = {Singh, Akanksha
Kurmi, Vinod},
Title = {Selective Capability
Unlearning in End-to-End
Spoken Language
Understanding},
Booktitle = {Interspeech},
Year = {2026}
}
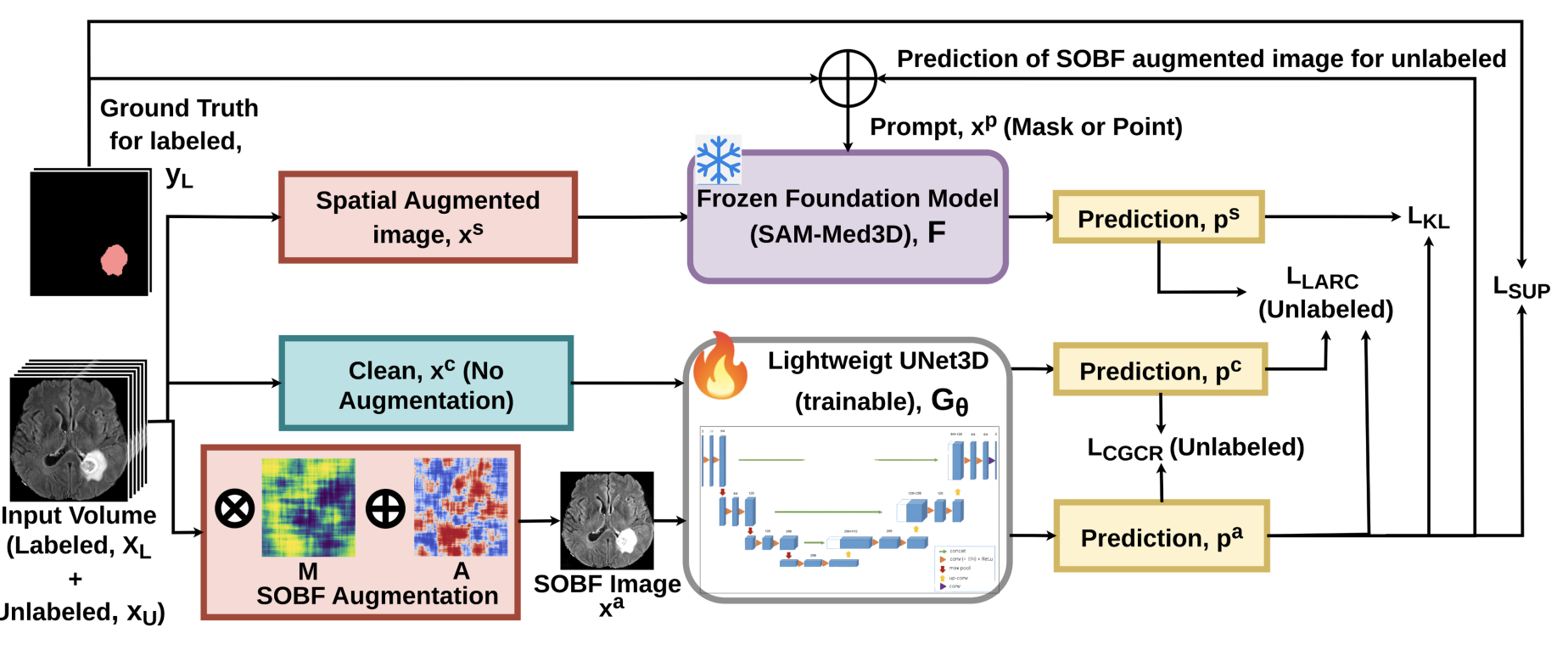
Foundation models provide strong anatomical priors that
can improve semi-supervised 3D MRI segmentation under limited anno-
tation. However, many approaches still rely on unstable teacher-student
updates and heuristic pseudo-labeling, which can accumulate errors when
learning from unlabeled volumes. In MRI, scanner-dependent intensity
inhomogeneity and distribution shifts further degrade robustness, es-
pecially in extreme low-label regimes with heterogeneous lesions. We
propose ReLiF-3D, a foundation-guided semi-supervised framework that
trains a lightweight 3D U-Net under supervision from a frozen volumetric
foundation model (SAM-Med3D) prior, avoiding EMA teacher drift while
retaining a stable spatial guide. Our main contribution is the Smooth Or-
thogonal Bias Field (SOBF), a paired-view generator that simulates re-
alistic MRI bias through orthogonal multiplicative and additive smooth
fields with a progressive strength schedule, producing anatomically con-
sistent yet scanner-shifted views for reliable consistency learning. To sta-
bilize unlabeled optimization, ReLiF-3D applies confidence-gated voxel
co-regularization to enforce consistency only on reliable agreements and
lesion-aware representation alignment guided by the SAM-Med3D prior.
Experiments on public BraTS and Left Atrium datasets with 1-5 labeled
volumes demonstrate significant improvements in overlap and boundary
metrics over SAM-assisted SSL baselines and state-of-the-art methods.
@inproceedings{jangid2026relif3d,
Author = {Jangid, Kunal
and Basu, Tanmay and
Kurmi, Vinod},
Title = {ReLiF-3D: Prior-Guided
Semi-Supervised 3D MRI Segmentation
via Robust Bias-Consistent Paired Views},
Booktitle = {MICCAI},
Year = {2026}
}
Fingerspelling, where words are spelled letter-by-letter using hand shapes, is essential for conveying names and technical terms
in sign languages. Recognition in low-resource languages is hindered by
limited data and weak word-level supervision. We introduce ISL-FSDense, which extends ISL-FS (an Indian Sign Language fingerspelling
dataset with only word-level labels) with character-level frame annotations, providing 1,308 segments with 125,661 frames across 14,682 character instances (99.1% validated accuracy). Models trained with dense
supervision achieve 4.87% Character Error Rate (CER), outperforming
word-level baselines (16.4%) and cross-lingual transfer from British Sign
Language (8.1%). The trained model also enables fingerspelling detection
(84.6% F1) without dedicated detection training, and automatic discovery of 11,700+ additional fingerspelling segments from videos lacking
sign-level annotations. Our results demonstrate that dense local annotations are more effective than cross-lingual transfer for low-resource sign
language fingerspelling recognition.
@inproceedings{kiran_icpr26,
Author = {R,Kiran.
and Kurmi, Vinod K
and Namboodiri, Vinay P
and Jawhar, CV},
Title = {Dense Frame Annotations
for Low-Resource ISL Fingerspelling
Recognition},
Booktitle = {ICPR},
Year = {2026}
}
Pretrained vision encoders are widely used as frozen, black-box feature extractors, yet they often inherit spurious correlations that disproportionately harm underrepresented groups. We introduce \textbf{PLD-Debias}, a fully black-box debiasing framework that requires neither access to backbone parameters nor demographic annotations. Our method integrates three components: (1) Rank-Regularized Amplification, a lightweight adapter that exaggerates latent spurious directions; (2) Unsupervised Pseudo-Bias Induction, which clusters amplified features to infer high-fidelity proxy bias labels; and (3) \emph{Bias-Guided Refinement}, combining supervised contrastive alignment with cluster-aware adaptive margins to purify representations and equalize decision boundaries. We theoretically show that these components jointly tighten a worst-group risk bound under spurious correlations. Empirically, PLD-Debias achieves state-of-the-art worst-group accuracy across CelebA, Waterbirds, and CMNIST, improving performance by 3--5 points over prior black-box methods while maintaining average accuracy. Remarkably, our pseudo-bias labels align with ground-truth bias annotations at over 90% fidelity, enabling oracle-level robustness without demographic supervision. Our results demonstrate that fairness and utility can be achieved through a plug-and-play classifier adapter for any frozen foundation model.
@inproceedings{rajeev_cvpr26,
Author = {Dwivedi, Rajeev R,
and Dangwal, Anshuman,
and Kurmi, Vinod},
Title = {Rank-Guided Pseudo-Bias
Learning for Robust Black-Box
Adaptation },
Booktitle = {CVPR},
Year = {2026}
}
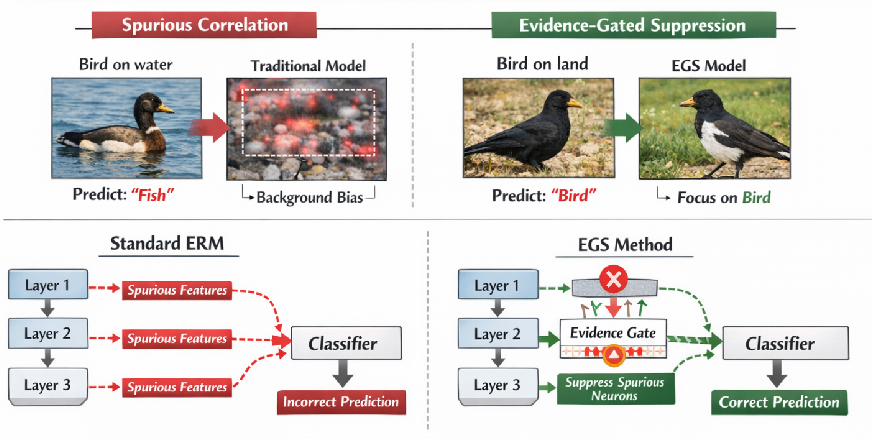
Deep models often exploit spurious correlations (e.g., backgrounds or dataset artifacts), hurting worst-group performance. We propose \textbf{Evidence-Gated Suppression (EGS)}, a lightweight, plug-in regularizer that intervenes inside the network during training. EGS tracks a class-conditional, confidence-weighted contribution for each neuron (more negative
stronger support) and applies a percentile-based, multiplicative decay to the most extreme contributors, reducing overconfident shortcut pathways while leaving other features relatively more influential. EGS integrates with standard ERM, requires no group labels, and adds
training overhead. We provide analysis linking EGS to minority-margin gains, path-norm-like capacity control, and stability benefits via EMA-smoothed gating. Empirically, EGS improves worst-group accuracy and calibration vs.\ ERM and is competitive with state-of-the-art methods across spurious-correlation benchmarks (e.g., Waterbirds, CelebA, BAR, COCO), while maintaining strong average accuracy. These results suggest that regulating internal evidence flow is a simple and scalable route to robustness without group labels.
@inproceedings{rajeev_iclr26,
Author = {Dwivedi, Rajeev R,
and Kalagond, Mohammedkaif,
and M.Patel, Niramay
and Kurmi, Vinod},
Title = {Regulating Internal Evidence
Flows for Robust Learning Under Spurious
Correlations},
Booktitle = {ICLR},
Year = {2026}
}
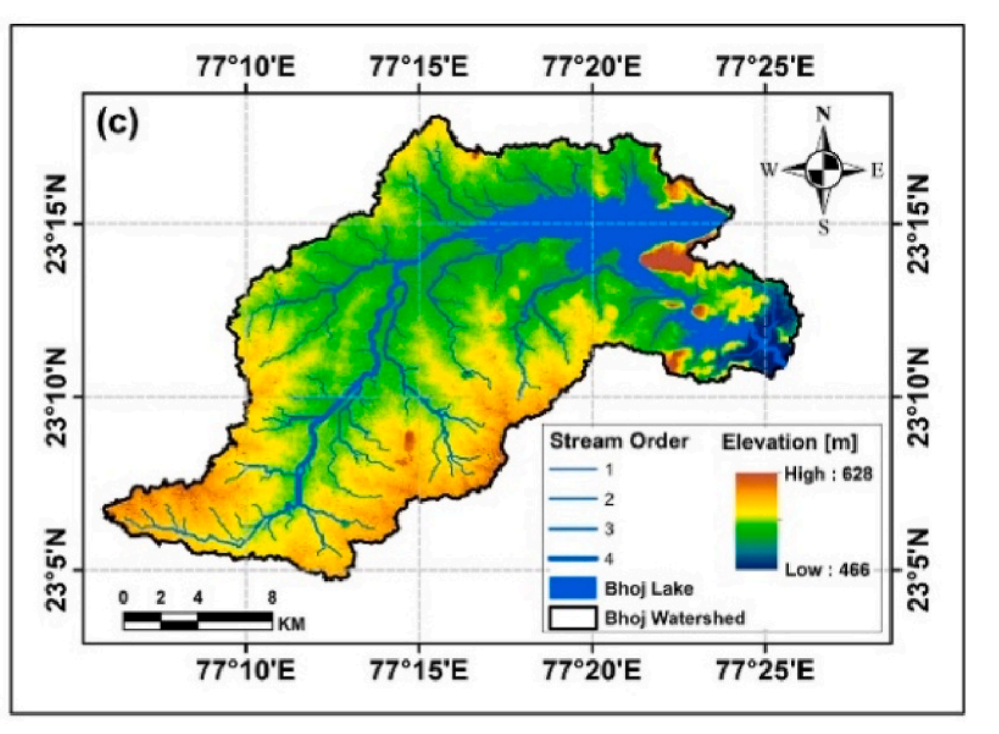
Surface water bodies such as lakes and wetlands play a vital role in ecological stability and urban water security, yet long-term monitoring remains challenging due to cloud contamination, sensor discontinuities, and limited in situ observations. This study presents a hybrid AI framework to reconstruct and model monthly water surface area (WSA) of Bhojtal Lake, a Ramsar-designated urban wetland in Central India, over 1990–2022 under historical and warming scenarios. Spatial gaps in Landsat-derived JRC Global Surface Water data were first addressed using a mode-based kernel correction, supported by an objective kernel-selection protocol. Months with extensive spatial corruption were excluded from spatial correction and handled through temporal modeling. Remaining temporal gaps in the WSA series were filled using a Bayesian-optimized Feedforward Neural Network (FNN) driven by lagged hydroclimatic variables, including precipitation, temperature, evapotranspiration, and soil moisture. Future WSA dynamics were simulated using a recursive Long Short-Term Memory (LSTM) ensemble, trained and evaluated on the corrected historical record and forced with climate inputs representing a stabilized +2 °C warming level. The framework demonstrates strong skill in WSA reconstruction and prediction (R2 ≈ 0.9; RMSE ≈ 2–3 km2). Ensemble simulations reveal pronounced seasonal asymmetry and an increased frequency of low-WSA months under warming conditions, indicating heightened drought susceptibility. Overall, the study presents a transferable, data-efficient framework that integrates remote sensing, climate forcing, and artificial intelligence to support long-term monitoring and climate-impact assessment of urban wetlands, contributing to climate-resilient water management and SDG-aligned planning in data-limited settings.
@inproceedings{Nath_remote26,
Author = {Nath, Roshan,
and Swarnkar, Somil,
and Poonia, Vikas
and Kurmi, Vinod},
Title = {Hybrid AI modelling
for imputation and modelling of
remotely sensed surface water in
climate-sensitive wetland},
Booktitle = {Remote Sensing Applications:
Society and Environment},
Year = {2026}
}
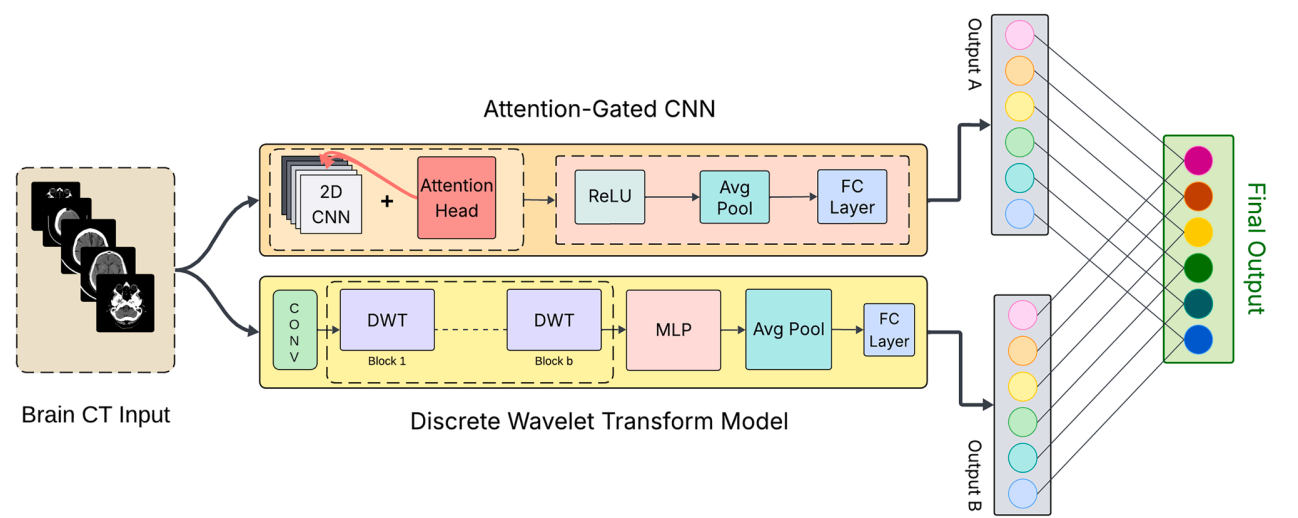
Brain hemorrhage, or Intracranial Hemorrhage (ICH), is a critical medical condition requiring rapid diagnosis.
Existing Convolutional Neural Network (CNN) models often struggle to differentiate similar hemorrhage subtypes like Epidural (EDH) and Subdural (SDH) due to a lack of specific spatial feature identification. This study
aims to develop a robust classification framework to address this challenge. We propose an ensemble framework
combining two complementary models. The first is an attention-gated 2D CNN designed to highlight subtle hemorrhagic regions. The second is a multi-level Discrete Wavelet Transform (DWT) model that analyzes images in
the frequency domain to capture deeper contextual and textural information from the 3D brain volume. The
proposed ensemble model was evaluated on the RSNA, CQ500, and a new GMC clinical dataset. The empirical
study demonstrates that our model consistently outperforms state-of-the-art methods across standard evaluation
metrics, including accuracy, macro-averaged AUC-ROC, specificity, sensitivity, and F1-score. The novel ensembling of an attention-gated CNN and a DWT-based model provides a more comprehensive feature representation,
leading to significantly improved accuracy and robustness in ICH classification, particularly in distinguishing
challenging subtypes like EDH and SDH.
@inproceedings{srutanik_Neuroscience26,
Author = {Bhaduri,Bhaduri
and Mondal, Rasel
and Sarangi, Prateek
and Kurmi, Vinod
and Goyal, Swati
and Kaushal, Lovely
and Sodani, Mahek
and Basu,Tanmay },
Title = {Attention-Gated CNN
and discrete wavelet transform
based ensemble
framework for brain
hemorrhage classification},
Booktitle = {Neuroscience Informatics},
Year = {2026}
}
We present HARMONY, a unified generative model for resolution-invariant NIR-to-RGB colorization that balances chromatic realism with structural fidelity. The proposed model combines (i) a combined loss term consisting of global color statistics alignment through differentiable histogram matching, and image quality measure to quantify perceptual similarity, (ii) local hue–saturation priors injected via SPADE to stabilize chromatic reconstruction, and (iii) texture-aware supervision within a Mamba backbone to preserve fine details. Additionally, we introduce an adaptive-resolution inference engine that further enables high-resolution translation without sacrificing quality. NIR-to-RGB system that simultaneously enforces global color statistics and local chromatic consistency, while scaling to native resolutions without compromising texture fidelity or generalization. Extensive evaluations on FANVID, OMSIV, VCIP2020, and RGB2NIR using different evaluation metrics demonstrate consistent improvements over state-of-the-art baseline methods. HARMONY produces images with sharper textures, more natural colors, resulting in significant gains as per perceptual metrics. These results position HARMONY as a scalable and effective solution for NIR-to-RGB translation across diverse imaging scenarios..
@inproceedings{abhinav_wacv26,
Author = {Abhinav,
and Dwivedi, Rajeev R,
and Das, Samiran
and Kurmi, Vinod},
Title = {Histogram Assisted
Quality Aware Generative
Model for Resolution
Invariant
NIR Image Colorization},
Booktitle = {WACV},
Year = {2026}
}
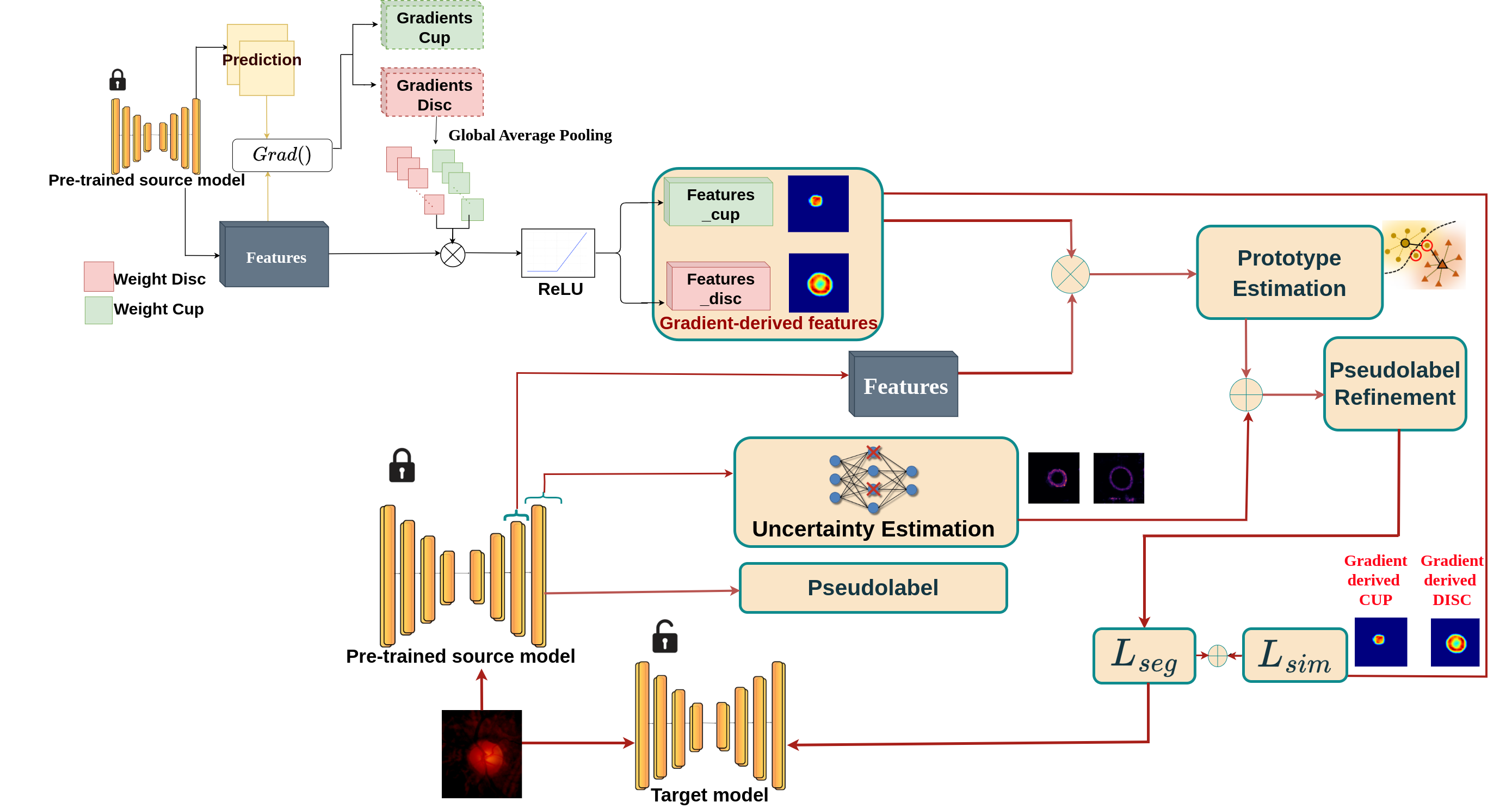
Accurate segmentation of the optic disc and cup is critical for the early diagnosis and management of ocular diseases such as glaucoma. However, segmentation models trained on one dataset often suffer significant performance degradation when applied to target data acquired under different imaging protocols or conditions. To address this challenge, we propose \textbf{Grad-CL}, a novel source-free domain adaptation framework that leverages a pre-trained source model and unlabeled target data to robustly adapt segmentation performance without requiring access to the original source data. Grad-CL combines a gradient-guided pseudolabel refinement module with a cosine similarity–based contrastive learning strategy. In the first stage, salient class-specific features are extracted via a gradient-based mechanism, enabling more accurate uncertainty quantification and robust prototype estimation for refining noisy pseudolabels. In the second stage, a contrastive loss based on cosine similarity is employed to explicitly enforce inter-class separability between the gradient-informed features of the optic cup and disc. Extensive experiments on challenging cross-domain fundus imaging datasets demonstrate that Grad-CL outperforms state-of-the-art unsupervised and source-free domain adaptation methods, achieving superior segmentation accuracy and improved boundary delineation.
@inproceedings{rini_bmvc25,
Author = {Thakur,Rini S,
and Dwivedi, Rajeev R
and Kurmi, Vinod},
Title = {Grad-CL: Source
Free Domain Adaptation
with Gradient Guided
Feature Disalignment},
Booktitle = {BMVC},
Year = {2025}
}
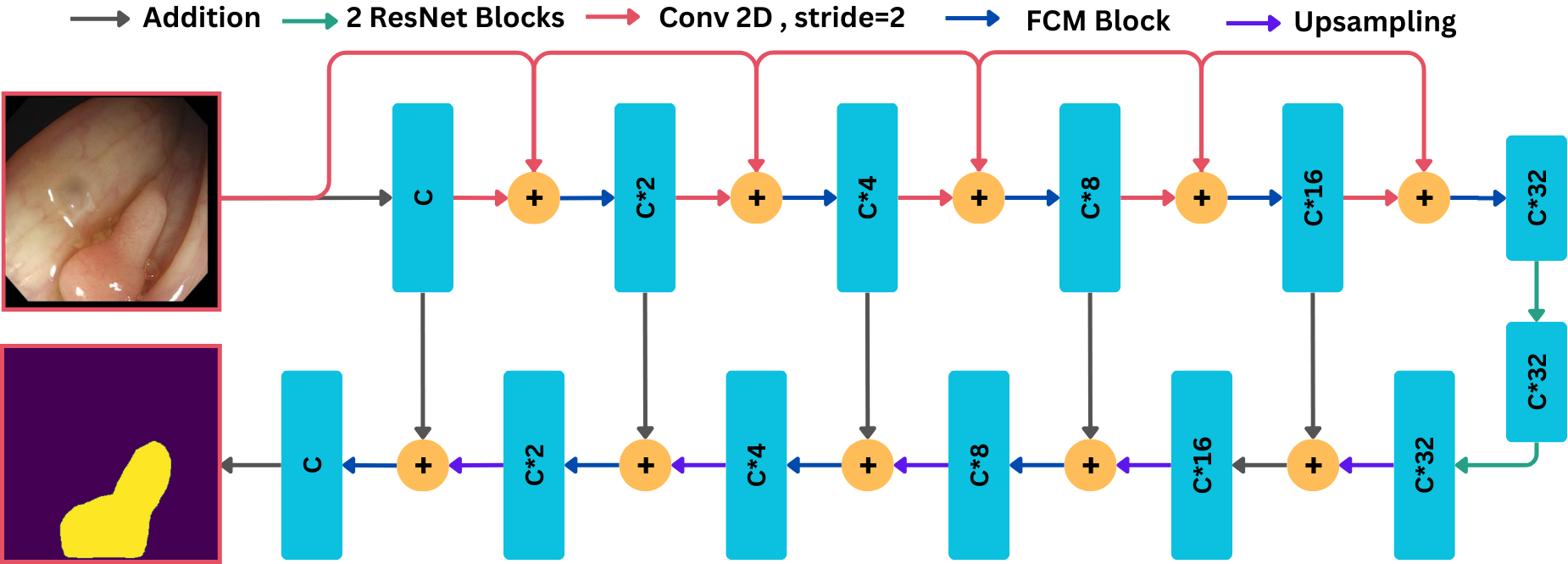
Accurate polyp and cardiac segmentation for early detection and treatment is essential for the diagnosis and treatment planning of cancer-like diseases. Traditional convolutional neural network (CNN) based models have represented limited generalizability, robustness, and inability to handle uncertainty, which affects the segmentation performance. To solve these problems, this paper introduces CLFSeg, an encoder-decoder based framework that aggregates the Fuzzy-Convolutional (FC) module leveraging convolutional layers and fuzzy logic. This module enhances the segmentation performance by identifying local and global features while minimizing the uncertainty, noise, and ambiguity in boundary regions, ensuring computing efficiency.
In order to handle class imbalance problem while focusing on the areas of interest with tiny and boundary regions, binary cross-entropy (BCE) with dice loss is incorporated. Our proposed model exhibits exceptional performance on four publicly available datasets, including CVC-ColonDB, CVC-ClinicDB, EtisLaribPolypDB, and ACDC.
Extensive experiments and visual studies show CLFSeg surpasses the existing SOTA performance and focuses on relevant regions of interest in anatomical structures. The proposed CLFSeg improves performance while ensuring computing efficiency, which makes it a potential solution for real-world medical diagnostic scenarios.
@inproceedings{anshul_bmvc25,
Author = {Anshul, Kaushal
and Jangid, Kunal
and Kurmi, Vinod},
Title = {CLFSeg: A Fuzzy-Logic
based Solution for Boundary
Clarity and Uncertainty
Reduction in Medical
Image Segmentation},
Booktitle = {BMVC},
Year = {2025}
}
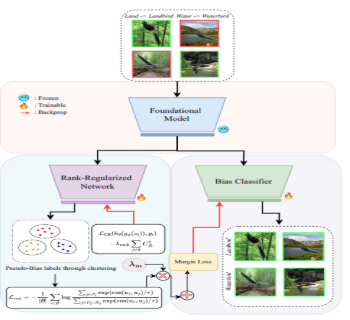
Real-world images frequently exhibit multiple overlapping biases,
including textures, watermarks, gendered makeup, scene-object pair-
ings, etc. These biases collectively impair the performance of modern
vision models, undermining both their robustness and fairness. Ad-
dressing these biases individually proves inadequate, as mitigating
one bias often permits or intensifies others. We tackle this multi-
bias problem with Generalized Multi-Bias Mitigation (GMBM), a
lean two-stage framework that needs group labels only while train-
ing and minimizes bias at test time. First, Adaptive Bias-Integrated
Learning (ABIL) deliberately identifies the influence of known short-
cuts by training encoders for each attribute and integrating them with
the main backbone, compelling the classifier to explicitly recognize
these biases. Then Gradient-Suppression Fine-Tuning prunes those
very bias directions from the backbone’s gradients, leaving a sin-
gle compact network that ignores all the shortcuts it just learned to
recognize. Moreover we find that existing bias metrics break under
subgroup imbalance and train–test distribution shifts, so we intro-
duce Scaled Bias Amplification (SBA): a test-time measure that dis-
entangles model-induced bias amplification from distributional dif-
ferences. We validate GMBM on FB-CMNIST, CelebA, and COCO,
where we boost worst-group accuracy, halve multi-attribute bias am-
plification, and set a new low in SBA—even as bias complexity and
distribution shifts intensify—making GMBM the first practical, end-
to-end multi-bias solution for visual recognition.
@inproceedings{rajeevr_ecai25,
Author = {Dwivedi, Rajeev R
and Kumar, Ankur
and Kurmi, Vinod},
Title = {Multi-Attribute
Bias Mitigation
via Representation
Learning},
Booktitle = {ECAI},
Year = {2025}
}
Spectral-Temporal Attention for Robust Change Detection
Mayank Thakur, Radhe Shyam Sharma, Vinod K Kurmi, Raj Samant, Badri N Patro IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025, Hangzhou, China.
Change detection has been used for various tasks
for a long time. With advancements in robotic systems and
computer vision, change detection techniques can be further
explored for diverse applications. Current state-of-the-art methods primarily use either satellite images or street-level images
to detect changes. However, the techniques used for these two
types of images differ substantially, though their core objective
remains identical. We introduce a spectral-temporal attention network capable
of detecting changes in both satellite and street-level images
across multiple temporal instances. Additionally, we present
an indoor environmental dataset featuring significantly more
frequent changes is significantly higher. We analyze the impact
of temporal and spatial domain shifts on the performance of
various methods and demonstrate that performing attention in
the spectral domain not only enhances overall performance but
also increases robustness against spatial domain shifts.
@inproceedings{thakur_iros25,
Author = {Thakur,Mayank
and Sharma, Radhe Shyam
and Kurmi, Vinod K
and Samant, Raj
and Patro, Badri N},
Title = {Spectral-Temporal
Attention for Robust Change
Detection},
Booktitle = {IROS},
Year = {2025}
}
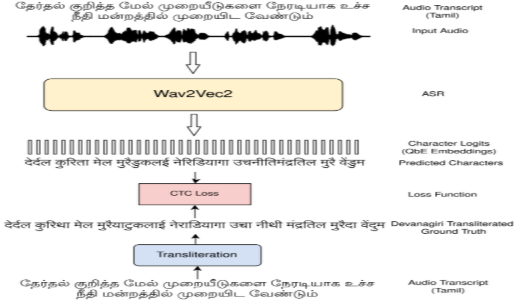
Multilingual Query-by-Example KWS using Transliteration
Kirandevraj R, Vinod K Kurmi, Vinay P Namboodiri, C V Jawahar Conference of the International Speech Communication Association (Interspeech) 2025, Rotterdam, Netherlands.
Query-by-Example Keyword Spotting (QbE KWS) detects query audio within target audio. A common approach for multilingual QbE KWS uses phoneme posteriors as representations, with a shared phoneme dictionary across languages. We propose a novel method that replaces phoneme-based representations with transliteration, unifying transcripts from multiple Indian languages into the Devanagari script, a text script used for Hindi and Marathi. We train a Multilingual ASR model to predict transliterated Devanagari text from audio across 10 Indian languages. The character logits from this ASR serve as both query and target audio features. Using the Kathbath dataset for training and the IndicSUPERB QbE evaluation set, our approach achieves significant improvements. The average MTWV increased from 0.015 (IndicSUPERB) to 0.504, and performance rose from 0.387 to 0.504, surpassing the best-performing Marathi ASR baseline. This demonstrates the effectiveness of transliteration for multilingual KWS.
@inproceedings{kiran_inter25,
Author = {R,Kiran.
and Kurmi, Vinod K
and Namboodiri, Vinay P
and Jawhar, CV},
Title = {Multilingual Query
-by-Example KWS using
Transliteration},
Booktitle = {InterSpeech},
Year = {2025}
}
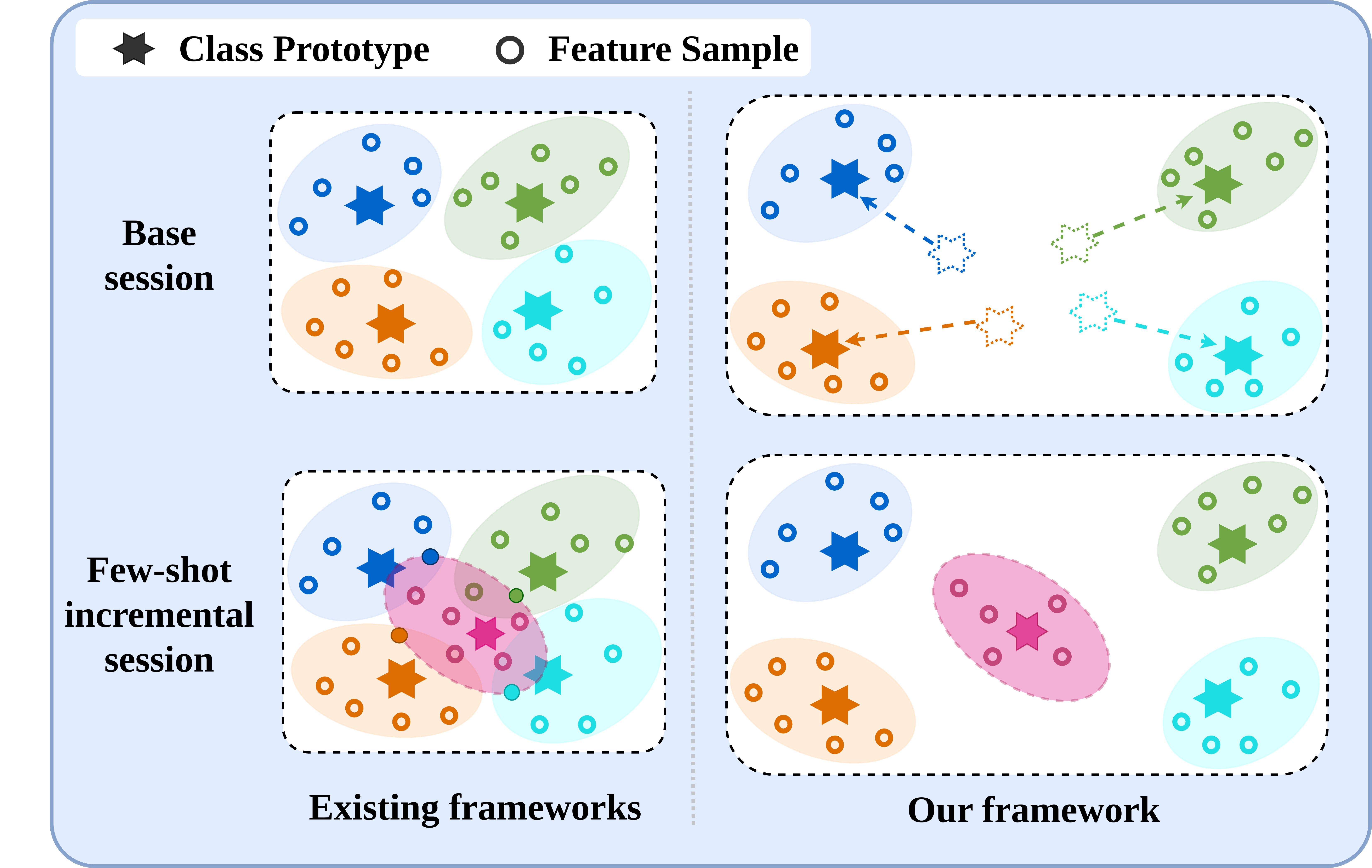
Few-shot class incremental learning implies the model to learn new classes while retaining knowledge of previously learned classes with a small number of training instances. Existing frameworks typically freeze the parameters of the previously learned classes during the incorporation of new classes. However, this approach often results in suboptimal class separation of previously learned classes, leading to overlap between old and new classes. Consequently, the performance of old classes degrades on new classes. To address these challenges, we propose a novel feature augmentation-driven contrastive learning framework designed to enhance the separation of previously learned classes to accommodate new classes. Our approach involves augmenting feature vectors and assigning proxy labels to these vectors. This strategy expands the feature space, ensuring seamless integration of new classes within the expanded space. Additionally, we employ a self-supervised contrastive loss to improve the separation between previous classes. We validate our framework through experiments on three FSCIL benchmark datasets: CIFAR100, miniImageNet, and CUB200. The results demonstrate that our Feature Augmentation driven Contrastive Learning framework significantly outperforms other approaches, achieving state-of-the-art performance.
@inproceedings{nema_wacv25,
Author = {Nema, Parinita
and Kurmi, Vinod },
Title = {Strategic Base Representation
Learning via Feature Augmentations for
Few-Shot Class Incremental Learning},
Booktitle = {WACV},
Year = {2025}
}
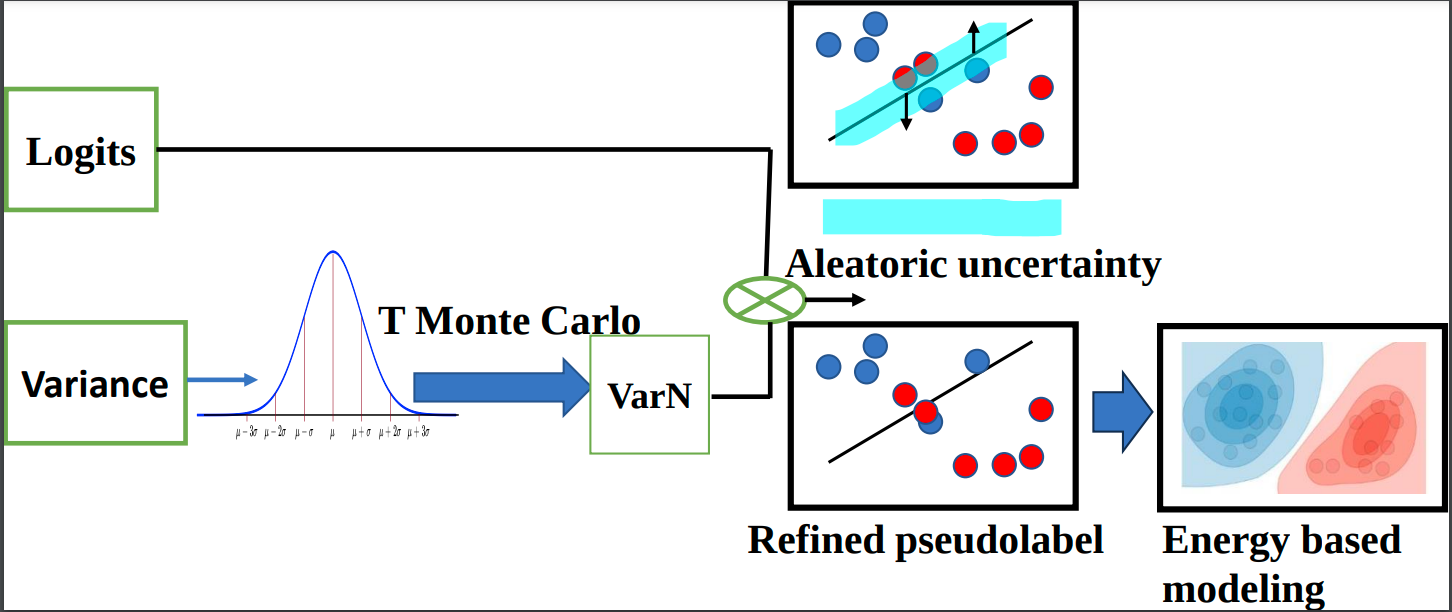
Semi-supervised semantic segmentation exploits both labeled and unlabeled images to overcome tedious and costly pixel-level annotation problem. Pseudolabel supervision is one of the core approaches of training networks with both pseudo labels and ground-truth labels. In this work, we use aleatoric or data uncertainty and energy based modeling in intersection-union pseudo supervised network. The inherent noise variations of the data are being modeled by the aleatoric uncertainty in a network with two predictive branches. The per-pixel variance parameter obtained from the network gives a quantitative idea about the data uncertainty. Moreover, energy-based loss realizes the potential of generative modeling on the downstream semi-supervised segmentation task. The aleatoric and energy loss is applied in conjunction with pseudo-intersection labels, pseudo-union labels, and ground-truth on the respective network branch. The comparative analysis with state-of-the-art methods has shown improvement in performance metrics.
@inproceedings{thakur_wacv25,
Author = {Thakur, Rini
and Kurmi, Vinod },
Title = {Uncertainty and Energy
based Loss Guided Semi-Supervised
Semantic Segmentation},
Booktitle = {WACV},
Year = {2025}
}
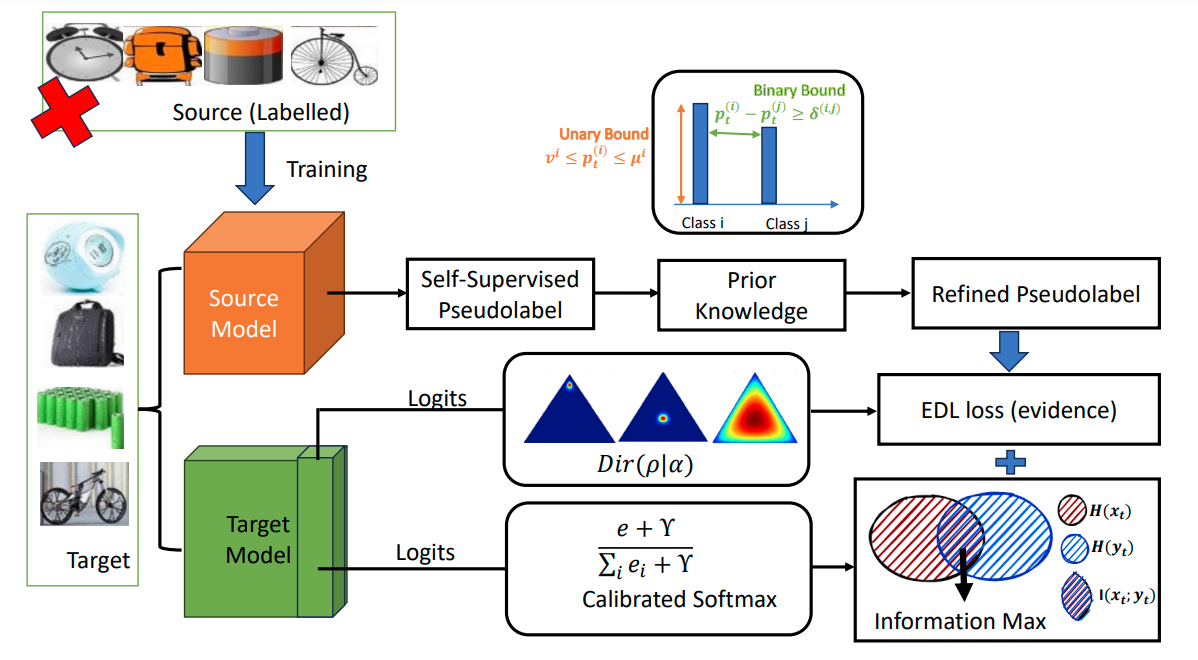
Source-free domain adaptation (SFDA) utilizes a pre-trained source model with unlabeled target data. Self-supervised SFDA techniques generate pseudolabels from the pre-trained source model, but these pseudolabels often contain noise due to domain discrepancies between the source and target domains. Traditional self-supervised SFDA techniques rely on deterministic model predictions using the softmax function, leading to unreliable pseudolabels. In this work, we propose to introduce predictive uncertainty and softmax calibration for pseudolabel refinement using evidential deep learning. The Dirichlet prior is placed over the output of the target network to capture uncertainty using evidence with a single forward pass. Furthermore, softmax calibration solves the translation invariance problem to assist in learning with noisy labels. We incorporate a combination of evidential deep learning loss and information maximization loss with calibrated softmax in both prior and non-prior target knowledge SFDA settings. Extensive experimental analysis shows that our method outperforms other state-of-the-art methods on benchmark datasets.
@inproceedings{rai_wacv25,
Author = {Rai Shivangi,
and Thakur, Rini
and Jangid, Kunal
and Kurmi, Vinod },
Title = {Label Calibration in
Source Free Domain Adaptation},
Booktitle = {WACV},
Year = {2025}
}
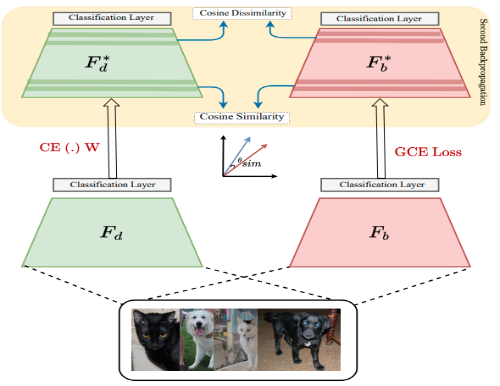
Deep neural networks trained on biased data often inadvertently learn unintended inference rules, particularly when labels are strongly correlated with biased features. Existing bias mitigation methods typically involve either a) predefining bias types and enforcing them as prior knowledge or b) reweighting training samples to emphasize biasconflicting samples over bias-aligned samples. However, both strategies address bias indirectly in the feature or sample space, with no control over learned weights, making it difficult to control the bias propagation across different layers. Based on this observation, we introduce a novel approach to address bias directly in the model’s parameter space, preventing its propagation across layers. Our method involves training two models: a bias model for biased features and a debias model for unbiased details, guided by the bias model. We enforce dissimilarity in the debias model’s later layers and similarity in its initial layers with the bias model, ensuring it learns unbiased low-level features without adopting biased high-level abstractions. By incorporating this explicit constraint during training, our approach shows enhanced classification accuracy and debiasing effectiveness across various synthetic and real-world datasets of different sizes. Moreover, the proposed method demonstrates robustness across different bias types and percentages of biased samples in the training data
@inproceedings{rajeevbmvc24_abs,
Author = {Dwivedi, Rajeev R
and Kumari, Priyadarshini
and Kurmi, Vinod },
Title = {CosFairNet:A Parameter-Space based
Approach for Bias Free Learning},
Booktitle = {BMVC},
Year = {2024}
}
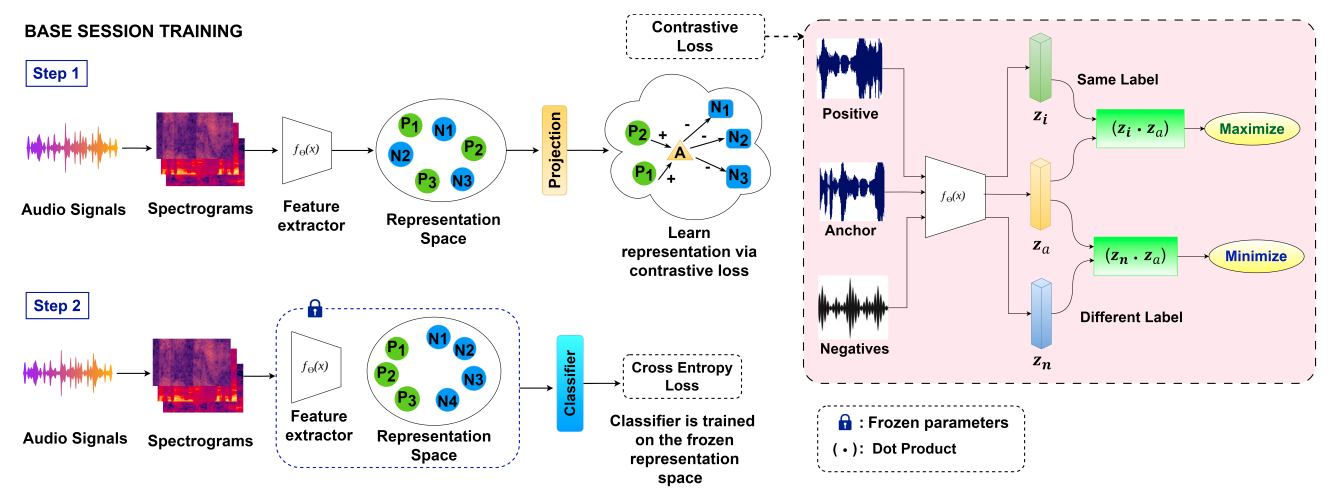
In machine learning applications, gradual data ingress is common, especially in audio processing where incremental learning is vital for real-time analytics. Few-shot class-incremental learning addresses challenges arising from limited incoming data. Existing methods often integrate additional trainable components or rely on a fixed embedding extractor post-training on base sessions to mitigate concerns related to catastrophic forgetting and the dangers of model overfitting. However, using cross-entropy loss alone during base session training is suboptimal for audio data. To address this, we propose incorporating supervised contrastive learning to refine the representation space, enhancing discriminative power and leading to better generalization since it facilitates seamless integration of incremental classes, upon arrival. Experimental results on NSynth and LibriSpeech datasets with 100 classes, as well as ESC dataset with 50 and 10 classes, demonstrate state-of-the-art performance.
@inproceedings{singh_intespeech24,
Author = {Singh Riyansha,
and Nema, Parinita
and Kurmi, Vinod },
Title = {Towards Robust Few-shot
Class Incremental Learning in Audio
Classification using Contrastive Representation},
Booktitle = {Interspeech},
Year = {2024}
}
Regression models are of fundamental importance in explicitly explaining the response variable in terms of covariates. However, point predictions of these models limit them from many real world applications. Heteroscedasticity is common in most real-world scenarios and is hard to model due to its randomness. The Gaussian process generally captures epistemic (model) uncertainty but fails to capture heteroscedastic aleatoric uncertainty. The framework of HetGP inherently captures both epistemic and aleatoric by placing independent GP’s priors on both mean function and error term. We propose the posthoc HetGP on the residuals of the trained deterministic neural network to obtain both epistemic and aleatoric uncertainty. The advantage of posthoc HetGP on residuals is that it can be extended to any type of model, since the model is assumed to be black-box that gives point predictions. We demonstrate our approach through simulation studies and UCI regression datasets.
@inproceedings{udbhav,
Author = {Udbhav Mallanna,Dalavai
and Dwivedi, Rajeev R
and Thakur, Rini S
and Kurmi, Vinod },
Title = {Quantifying Uncertainty
in Neural Networks through Residuals},
Booktitle = {CIKM},
Year = {2024}
}
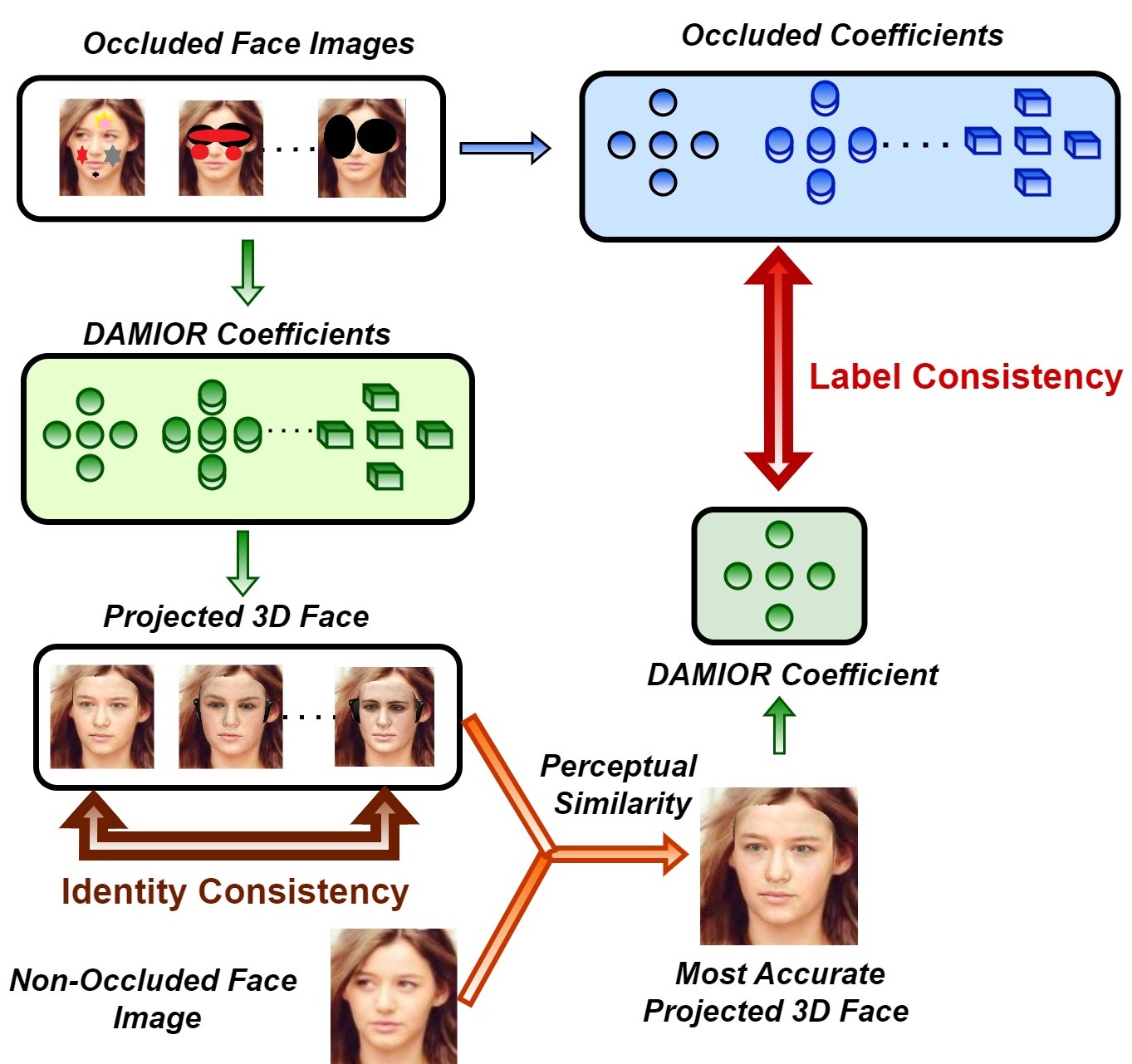
Recently, there have been significant advancements in the 3D face reconstruction field, largely driven by monocular image-based deep learning methods. However, these methods still face challenges in reliable deployments due to their sensitivity to facial occlusions and inability to maintain identity consistency across different occlusions within the same facial image. To address these issues, we propose two frameworks: Distillation Assisted Mono Image Occlusion Robustification (DAMIOR) and Duplicate Images Assisted Multi Occlusions Robustification (DIAMOR). The DAMIOR framework leverages the knowledge from the Occlusion Frail Trainer (OFT) network to enhance robustness against facial occlusions. Our proposed method overcomes the sensitivity to occlusions and improves reconstruction accuracy. To tackle the issue of identity inconsistency, the DIAMOR framework utilizes the estimates from DAMIOR to mitigate inconsistencies in geometry and texture, collectively known as identity, of the reconstructed 3D faces. We evaluate the performance of DAMIOR on two variations of the CelebA test dataset: empirical occlusions and irrational occlusions. Furthermore, we analyze the performance of the proposed DIAMOR framework using the irrational occlusion-based variant of the CelebA test dataset. Our methods outperform state-of-the-art approaches by a significant margin. For example, DAMIOR reduces the 3D vertex-based shape error by 41.1% and the texture error by 21.8% for empirical occlusions. Besides, for facial data with irrational occlusions, DIAMOR achieves a substantial decrease in shape error by 42.5% and texture error by 30.5%. These results demonstrate the effectiveness of our proposed methods.
@inproceedings{hitika_ivc3,
Author = {Tiwari, Hitika
and Kurmi, Vinod K
and Subramanian,
Venkatesh K and
Chen, Yong Sheng },
Title = {Distilling Knowledge
for Occlusion Robust Monocular
3D Face Reconstruction},
Booktitle = {InterSpeech},
Year = {2022}
}
Generalized Keyword Spotting using ASR embeddings
Kirandevraj R, Vinod K Kurmi, Vinay P Namboodiri, C V Jawahar Conference of the International Speech Communication Association (Interspeech) 2022, Incheon Korea.
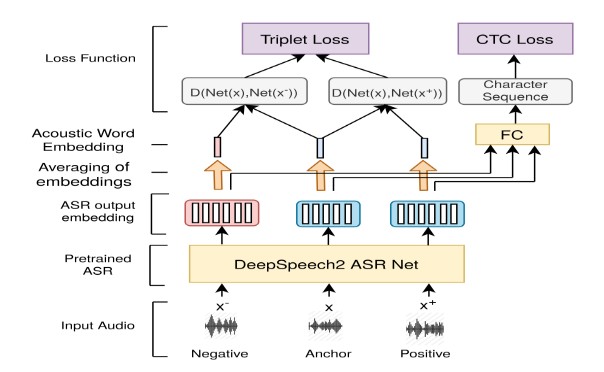
Keyword Spotting (KWS) detects a set of pre-defined spoken keywords. Building a KWS system for an arbitrary set re- quires massive training datasets. We propose to use the text transcripts from an Automatic Speech Recognition (ASR) sys- tem alongside triplets for KWS training. The intermediate rep- resentation from the ASR system trained on a speech corpus is used as acoustic word embeddings for keywords. Triplet loss is added to the Connectionist Temporal Classification (CTC) loss in the ASR while training. This method achieves an Average Precision (AP) of 0.843 over 344 words unseen by the model trained on the TIMIT dataset. In contrast, the Multi-View re- current method that learns jointly on the text and acoustic em- beddings achieves only 0.218 for out-of-vocabulary words. This method is also applied to low-resource languages such as Tamil by converting Tamil characters to English using transliteration. This is a very challenging novel task for which we provide a dataset of transcripts for the keywords. Despite our model not generalizing well, we achieve a benchmark AP of 0.321 on over 38 words unseen by the model on the MSWC Tamil keyword set. The model also produces an accuracy of 96.2% for classifi- cation tasks on the Google Speech Commands dataset.
@inproceedings{kiran_inter22,
Author = {R,Kiran.
and Kurmi, Vinod K
and Namboodiri, Vinay P
and Jawhar, CV},
Title = {Generalized Keyword
Spotting using ASR embeddings},
Booktitle = {InterSpeech},
Year = {2022}
}
Gradient Based Activations for Accurate Bias-Free Learning Vinod K Kurmi*, Rishabh Sharma*, Yash Vardhan Sharma*, Vinay P Namboodiri (*equal contributions) Proceedings of the AAAI Conference on Artificial Intelligence, (AAAI), Vancouver BC, Canada, 2022.
Bias mitigation in machine learning models is imperative, yet challenging. While several approaches have been proposed, one view towards mitigating bias is through adversarial learning. A discriminator is used to identify the bias attributes such as gender, age or race in question. This discriminator is used adversarially to ensure that it cannot distinguish the bias attributes. The main drawback in such a model is that it directly introduces a trade-off with accuracy as the features that the discriminator deems to be sensitive for discrimination of bias could be correlated with classification. In this work we solve the problem. We show that a biased discriminator can actually be used to improve this bias-accuracy tradeoff. Specifically, this is achieved by using a feature masking approach using the discriminator's gradients. We ensure that the features favoured for the bias discrimination are de-emphasized and the unbiased features are enhanced during classification. We show that this simple approach works well to reduce bias as well as improve accuracy significantly. We evaluate the proposed model on standard benchmarks. We improve the accuracy of the adversarial methods while maintaining or even improving the unbiasness and also outperform several other recent methods.
@inproceedings{kurmi_aaai22,
Author = {Kurmi,Vinod K.
and Sharma, Rishabh and
Sharma, Yash Vardhan and
Namboodiri, Vinay P},
Title = {Gradient Based
Activations for Accurate
Bias-Free Learning},
Booktitle = {AAAI},
Year = {2022}
}
3D face reconstruction from a monocular face image is a mathematically ill-posed problem. Recently, we observed a surge of interest in deep learning-based approaches to address the issue. These methods possess extreme sensitivity towards occlusions. Thus, in this paper, we present a novel context-learning-based distillation approach to tackle the occlusions in the face images. Our training pipeline focuses on distilling the knowledge from a pre-trained occlusion-sensitive deep network. The proposed model learns the context of the target occluded face image. Hence our approach uses a weak model (unsuitable for occluded face images) to train a highly robust network towards partially and fully-occluded face images. We obtain a landmark accuracy of $0.77$ against $5.84$ of recent state-of-the-art-method for real-life challenging facial occlusions. Also, we propose a novel end-to-end training pipeline to reconstruct 3D faces from multiple variations of the target image per identity to emphasize the significance of visible facial features during learning. For this purpose, we leverage a novel composite multi-occlusion loss function. Our multi-occlusion per identity model shows a dip in the landmark error by a large margin of $6.67$ in comparison to a recent state-of-the-art method. We deploy the occluded variations of the CelebA validation dataset and AFLW2000-3D face dataset: naturally-occluded and artificially occluded, for the comparisons. We comprehensively compare our results with the other approaches concerning the accuracy of the reconstructed 3D face mesh for occluded face images..
@inproceedings{tiwati_wacv22,
Author = {Tiwari, H.
and Kurmi,Vinod Kumar
and Venkatesh, KS and
Chen,Yong-Sheng},
Title = {Occlusion Resistant Network
for 3D Face Reconstruction},
Booktitle = {WACV},
Year = {2022}
}
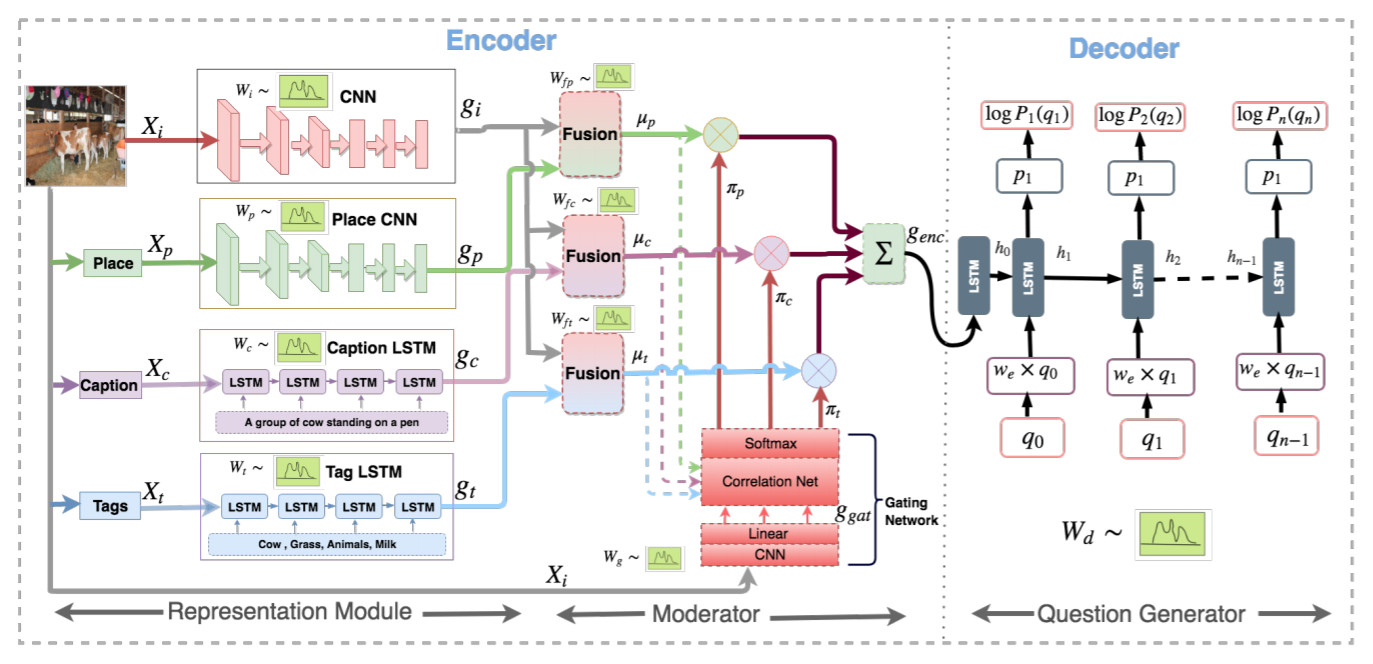
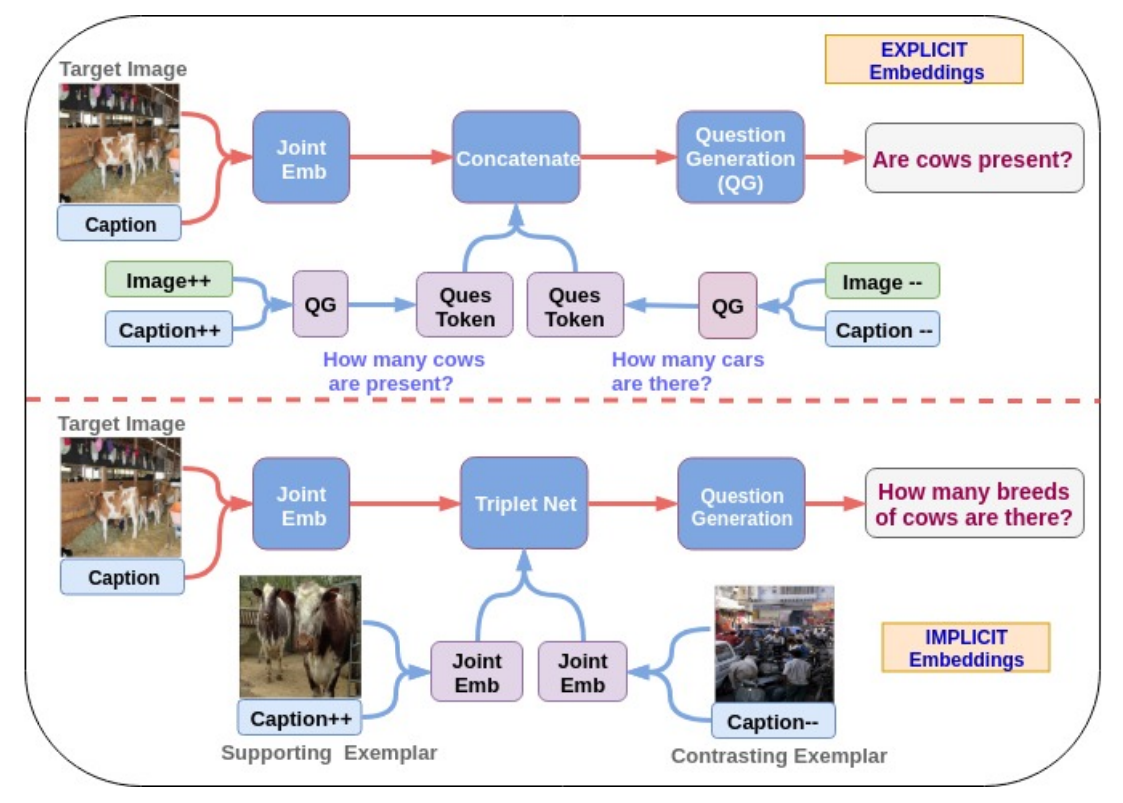
Generating natural questions from an image is a semantic task that requires using
vision and language modalities to learn multimodal representations. Images can have
multiple visual and language cues such as places, captions, and tags. In this paper,
we propose a principled deep Bayesian learning framework that combines these cues
to produce natural questions. We observe that with the addition of more cues and
by minimizing uncertainty in the among cues, the Bayesian network becomes more
confident. We propose a Minimizing Uncertainty of Mixture of Cues (MUMC), that
minimizes uncertainty present in a mixture of cues experts for generating probabilistic
questions. This is a Bayesian framework and the results show a remarkable similarity to
natural questions as validated by a human study. Ablation studies of our model indicate
that a subset of cues is inferior at this task and hence the principled fusion of cues is
preferred. Further, we observe that the proposed approach substantially improves over
state-of-the-art benchmarks on the quantitative metrics (BLEU-n, METEOR, ROUGE,
and CIDEr).
@inproceedings{patro_ivc_2,
Author = {Patro, Badri Narayana
and Kumar, Sandeep and Kurmi,
Vinod Kumar and Namboodiri, Vinay},
Title = {MUMC: Minimizing Uncertainty
of Mixture of Cues},
Booktitle = {Image and Vision
Computing,(IMAVIS)},
Year = {2021}
}
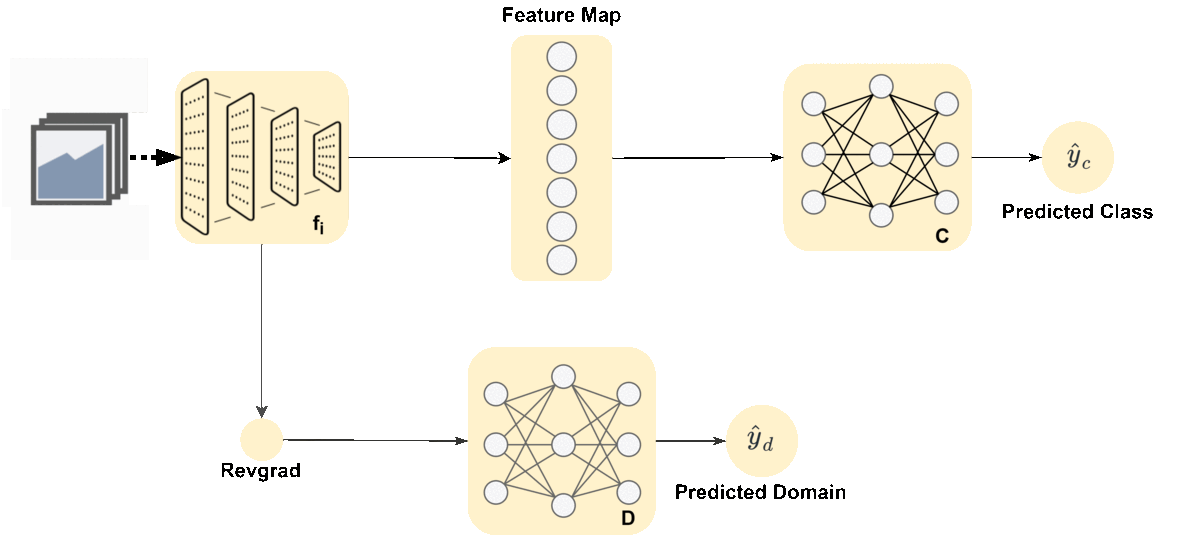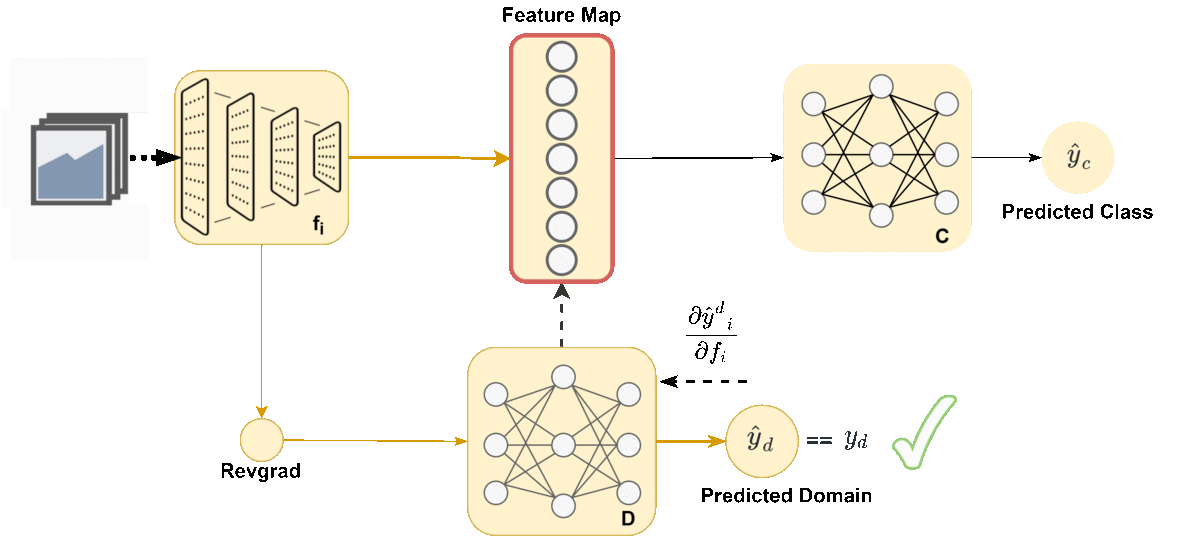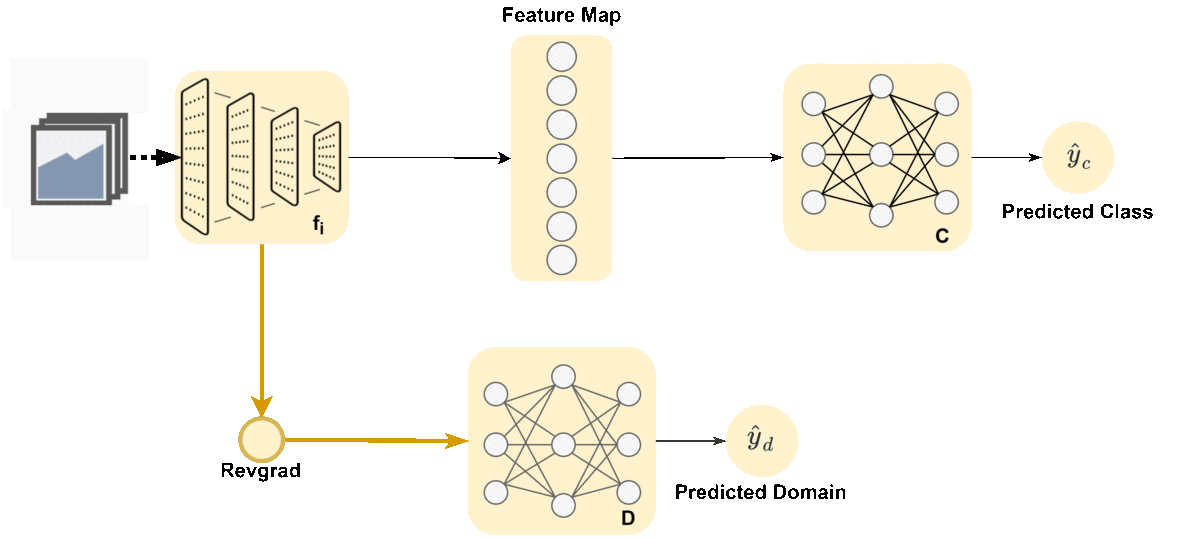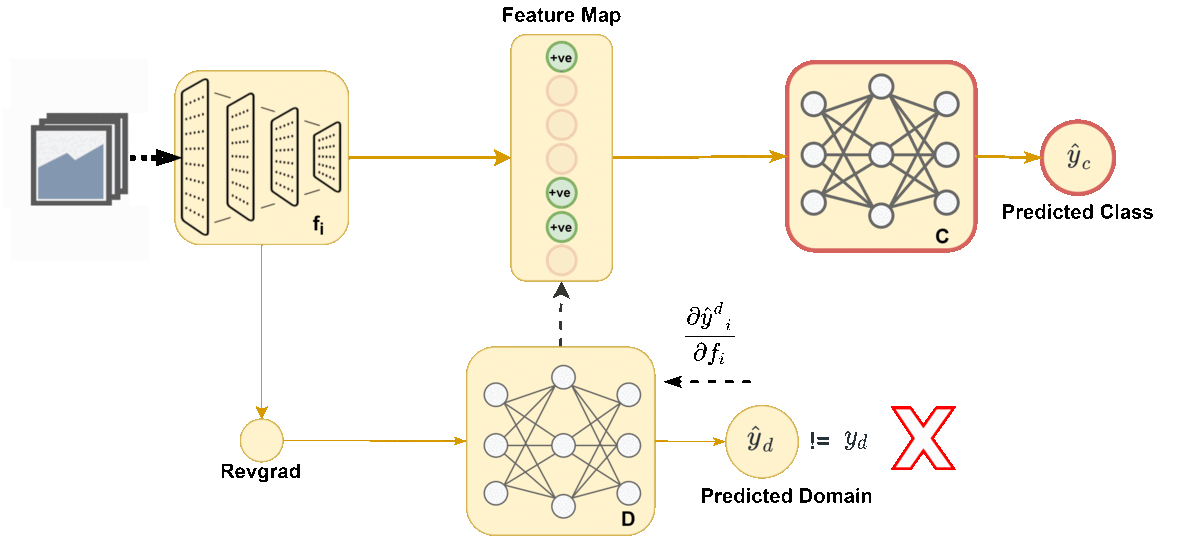
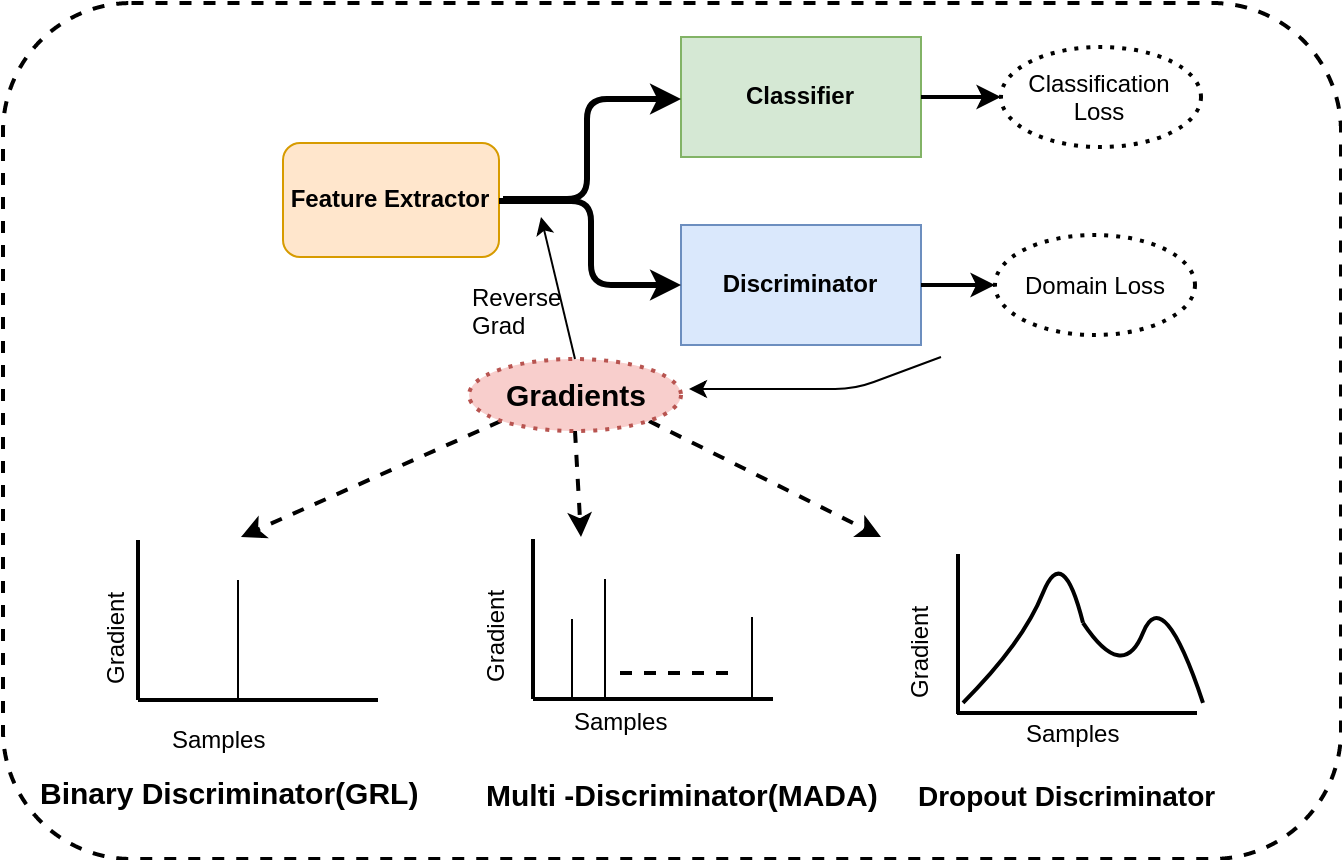
Adaptation of a classifier to new domains is one of the challenging problems in machine learning. This has been addressed using many deep and non-deep learning based methods. Among the methodologies used, that of adversarial learning is widely applied to solve many deep learning problems along with domain adaptation. These methods are based on a discriminator that ensures source and target distributions are close. However, here we suggest that rather than using a point estimate obtaining by a single discriminator, it would be useful if a distribution based on ensembles of discriminators could be used to bridge this gap. This could be achieved using multiple classifiers or using traditional ensemble methods.} In contrast, we suggest that a Monte Carlo dropout based ensemble discriminator could suffice to obtain the distribution based discriminator. Specifically, we propose a curriculum based dropout discriminator that gradually increases the variance of the sample based distribution and the corresponding reverse gradients are used to align the source and target feature representations.
@inproceedings{kurmi2021_idda_j,
Author = {Kurmi, Vinod Kumar and K S ,
Venaktesh and Namboodiri, Vinay},
Title = {Exploring Dropout
Discriminator for Domain Adaptation},
Booktitle = {Neurocomputing},
Year = {2021}
}
Understanding unsupervised domain adaptation has been an important task that has been well explored. However, the wide variety of methods have not analyzed the role of a classifier's performance in detail. In this paper, we thoroughly examine the role of a classifier in terms of matching source and target distributions. We specifically investigate the classifier ability by matching a) the distribution of features, b) probabilistic uncertainty for samples and c) certainty activation mappings. Our analysis suggests that using these three distributions does result in a consistently improved performance on all the datasets. Our work thus extends present knowledge on the role of the various distributions obtained from the classifier towards solving unsupervised domain adaptation.
@inproceedings{shanu,
Author = {Kumar, Shanu and
Kurmi, Vinod Kumar and Singh,
Praphul and Namboodiri, Vinay P},
Title = {Mitigating Uncertainty
of Classifier for Unsupervised Domain Adaptation},
Booktitle = {Preprint- arXiv},
Year = {2021}
}
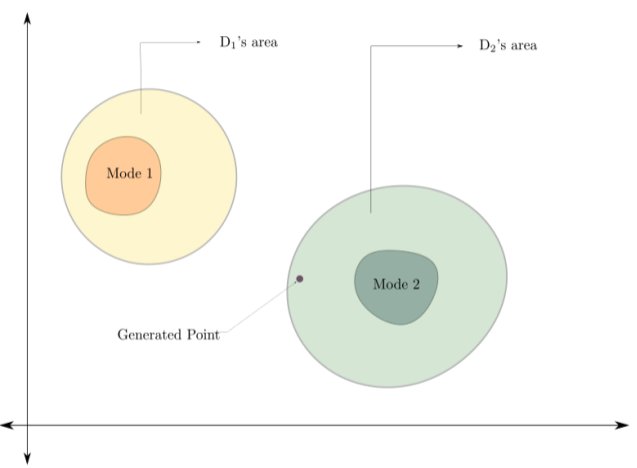
Generative adversarial networks (GANs) are very popular to generate realistic images, but they often suffer from the training instability issues and the phenomenon of mode loss. In order to attain greater diversity in GAN synthesized data, it is critical to solving the problem of mode loss. Our work explores probabilistic approaches to GAN modelling that could allow us to tackle these issues. We present Prb-GANs, a new variation that uses dropout to create a distribution over the network parameters with the posterior learnt using variational inference. We describe theoretically and validate experimentally using simple and complex datasets the benefits of such an approach. We look into further improvements using the concept of uncertainty measures. Through a set of further modifications to the loss functions for each network of the GAN, we are able to get results that show the improvement of GAN performance. Our methods are extremely simple and require very little modification to existing GAN architecture.
@inproceedings{george2021prb,
title={Prb-GAN: A Probabilistic
Framework for GAN Modelling},
author={George, Blessen and
Kurmi, Vinod K and Namboodiri, Vinay P},
journal={arXiv preprint arXiv:2107.05241},
year={2021}
}
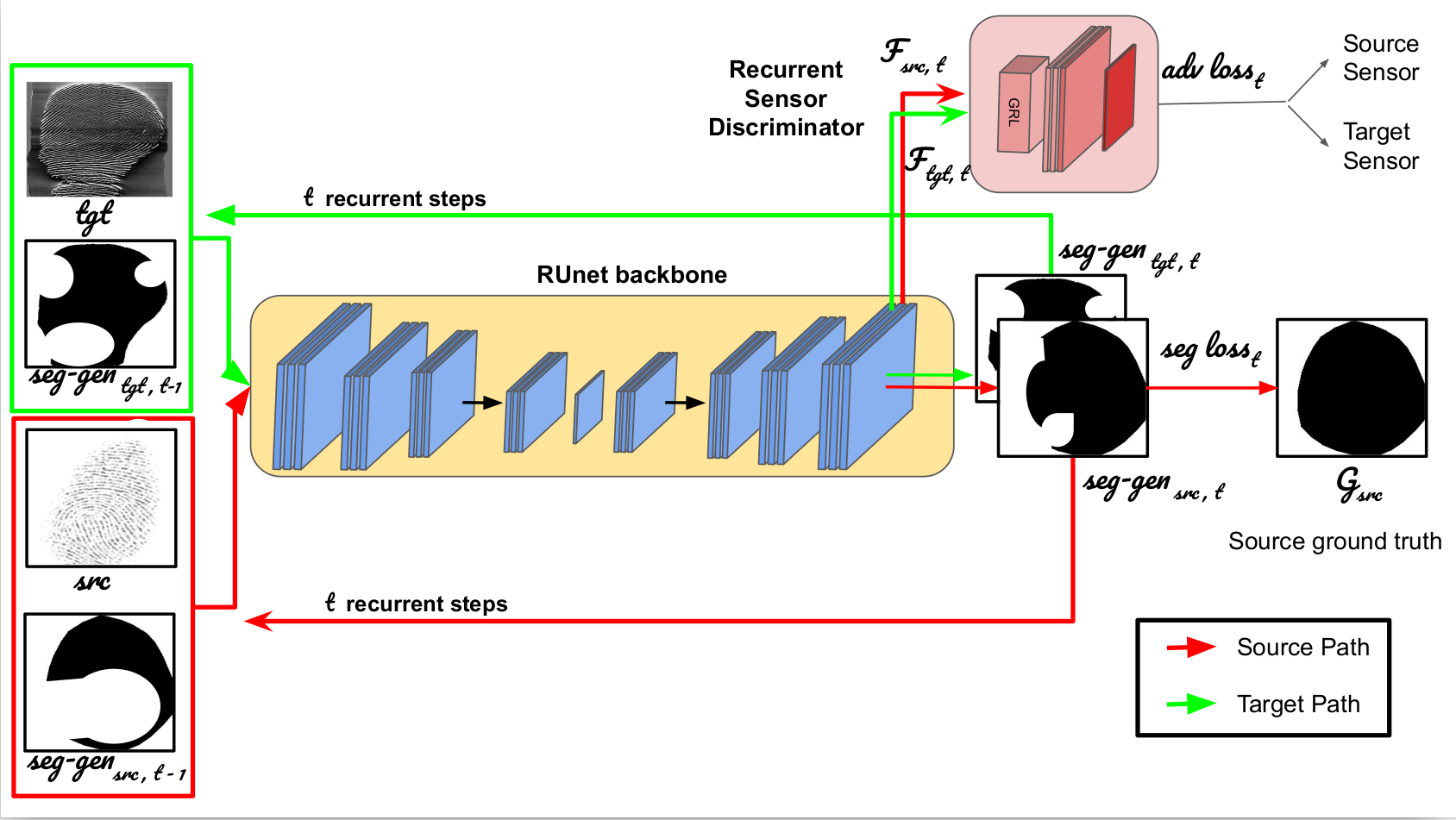
A fingerprint region of interest (roi) segmentation algorithm is designed to separate the foreground fingerprint from the background noise. All the learning based state-of-the-art fingerprint roi segmentation algorithms proposed in the literature are benchmarked on scenarios when both training and testing databases consist of fingerprint images acquired from the same sensors. However, when testing is conducted on a different sensor, the segmentation performance obtained is often unsatisfactory. As a result, every time a new fingerprint sensor is used for testing, the fingerprint roi segmentation model needs to be re-trained with the fingerprint image acquired from the new sensor and its corresponding manually marked ROI. Manually marking fingerprint ROI is expensive because firstly, it is time consuming and more importantly, requires domain expertise. In order to save the human effort in generating annotations required by state-of-the-art, we propose a fingerprint roi segmentation model which aligns the features of fingerprint images derived from the unseen sensor such that they are similar to the ones obtained from the fingerprints whose ground truth roi masks are available for training. Specifically, we propose a recurrent adversarial learning based feature alignment network that helps the fingerprint roi segmentation model to learn sensor-invariant features. Consequently, sensor-invariant features learnt by the proposed roi segmentation model help it to achieve improved segmentation performance on fingerprints acquired from the new sensor. Experiments on publicly available FVC databases demonstrate the efficacy of the proposed work.
@inproceedings{joshi021_1,
Author={Joshi, Indu and Kothari, Riya
and Utkarsh, Ayush and Kurmi, Vinod K
and Dantcheva,Antitza and Roy,
Sumantra Dutta and Kalra, Prem Kumar},
Title = {Sensor-invariant Fingerprint
ROI SegmentationUsing Recurrent
Adversarial Learning},
Booktitle = {IJCNN},
Year = {2021}
}
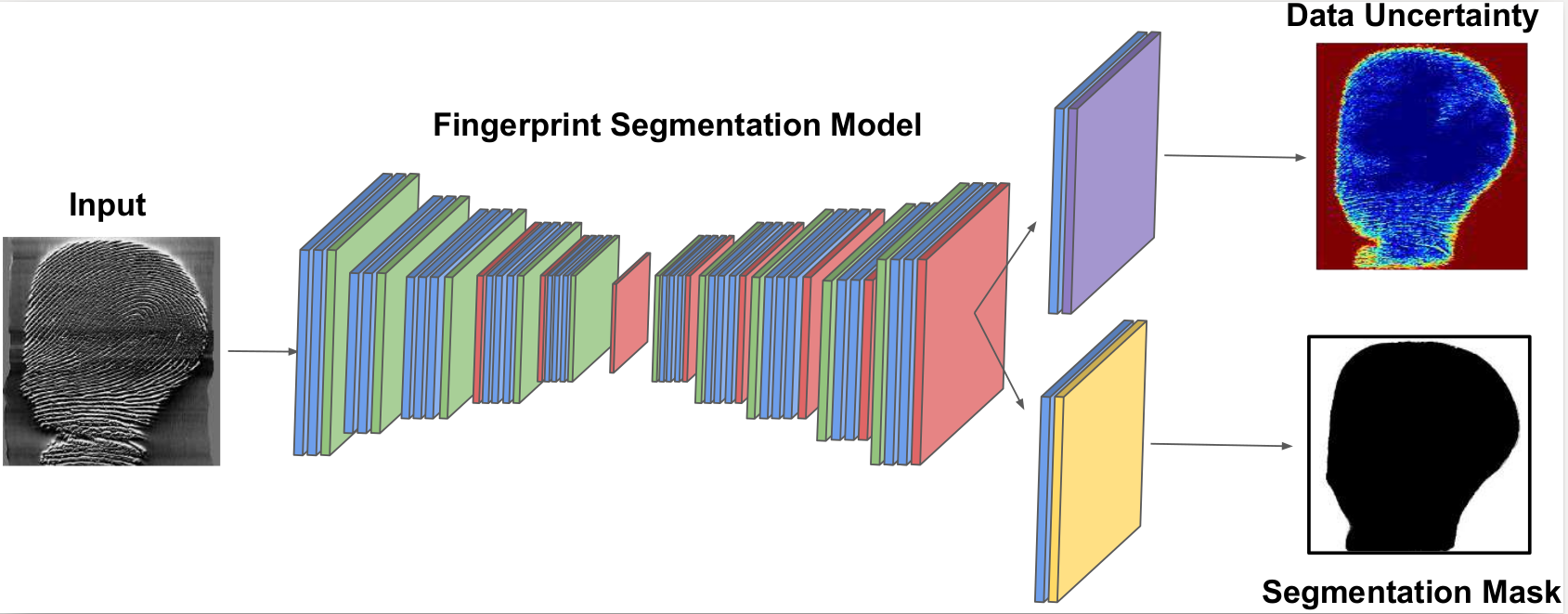
The effectiveness of fingerprint-based authentication systems on good quality fingerprints is established long back. However, the performance of standard fingerprint matching systems on noisy and poor quality fingerprints is far from satisfactory. Towards this, we propose a data uncertainty-based framework which enables the state-of-the-art fingerprint preprocessing models to quantify noise present in the input image and identify fingerprint regions with background noise and poor ridge clarity. Quantification of noise helps the model two folds: firstly, it makes the objective function adaptive to the noise in a particular input fingerprint and consequently, helps to achieve robust performance on noisy and distorted fingerprint regions. Secondly, it provides a noise variance map which indicates noisy pixels in the input fingerprint image. The predicted noise variance map enables the end-users to understand erroneous predictions due to noise present in the input image. Extensive experimental evaluation on 13 publicly available fingerprint databases, across different architectural choices and two fingerprint processing tasks demonstrate effectiveness of the proposed framework.
@inproceedings{joshi021_2,
Author={Joshi, Indu and Kothari, Riya
and Utkarsh, Ayush and Kurmi, Vinod K
and Dantcheva,Antitza and Roy,
Sumantra Dutta and Kalra, Prem Kumar},
Title = {Data Uncertainty Guided
Noise-awarePreprocessing Of Fingerprints},
Booktitle = {IJCNN},
Year = {2021}
}
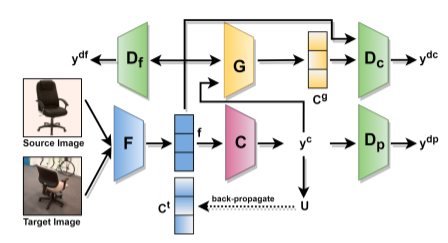
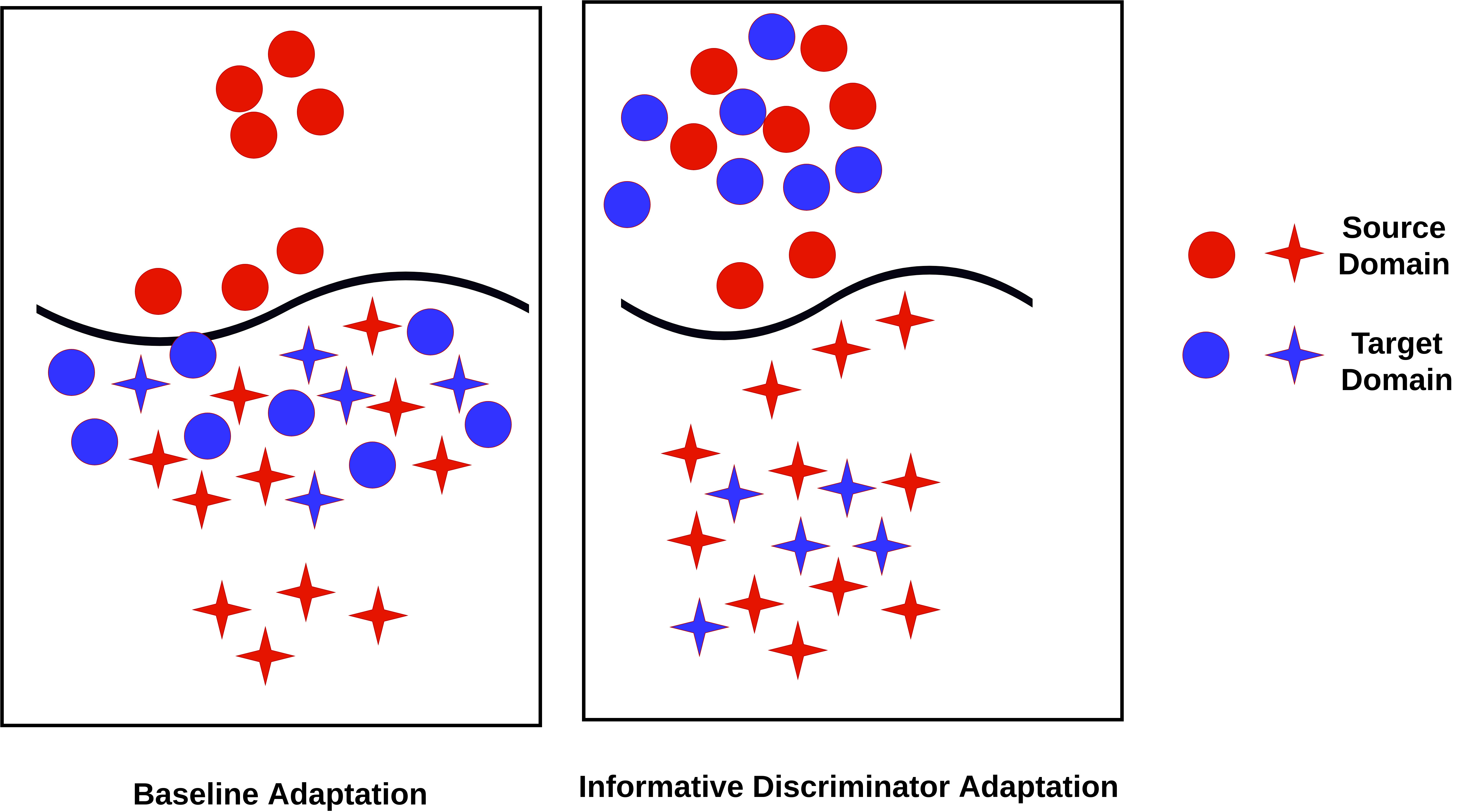
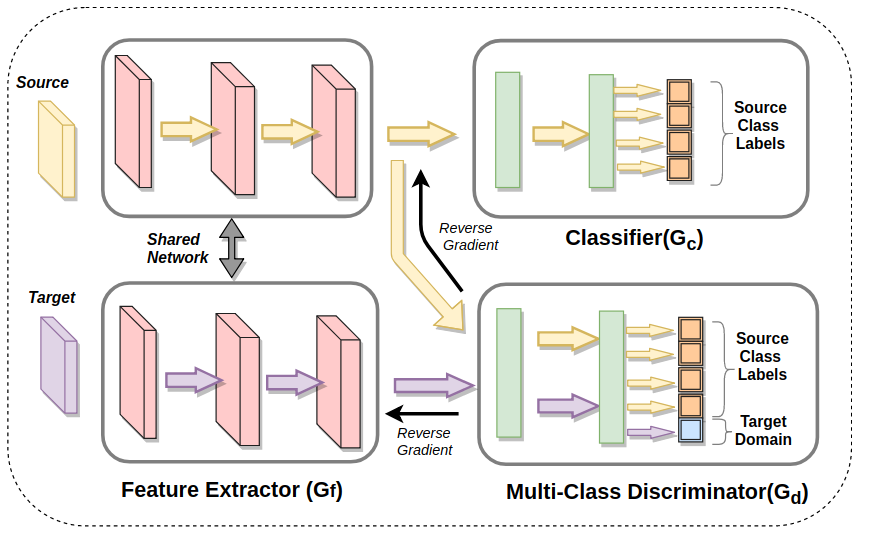
In this paper, we consider the problem of domain adaptation for multi-class classification, where we are provided a labeled set of examples in a source dataset and target dataset with no supervision. We tackle the mode collapse problem in adapting the classifier across domains. In this setting, we propose an adversarial learning-based approach using an informative discriminator. Our observation relies on the analysis that shows if the discriminator has access to all the information available, including the class structure present in the source dataset, then it can guide the transformation of features of the target set of classes to a more structured adapted space. Further, by training the informative discriminator using the more robust source samples, we are able to obtain better domain invariant features. Using this formulation, we achieve state-of-the-art results for the standard evaluation on benchmark datasets. We also provide detailed analysis, which shows that using all the labeled information results in an improved domain adaptation.
@inproceedings{kurmi2021_idda_j,
Author = {Kurmi, Vinod Kumar and K S ,
Venaktesh and Namboodiri, Vinay},
Title = {Informative Discriminator
for Domain Adaptation},
Booktitle = {Image and Vision Computing,(IMAVIS)},
Year = {2021}
}
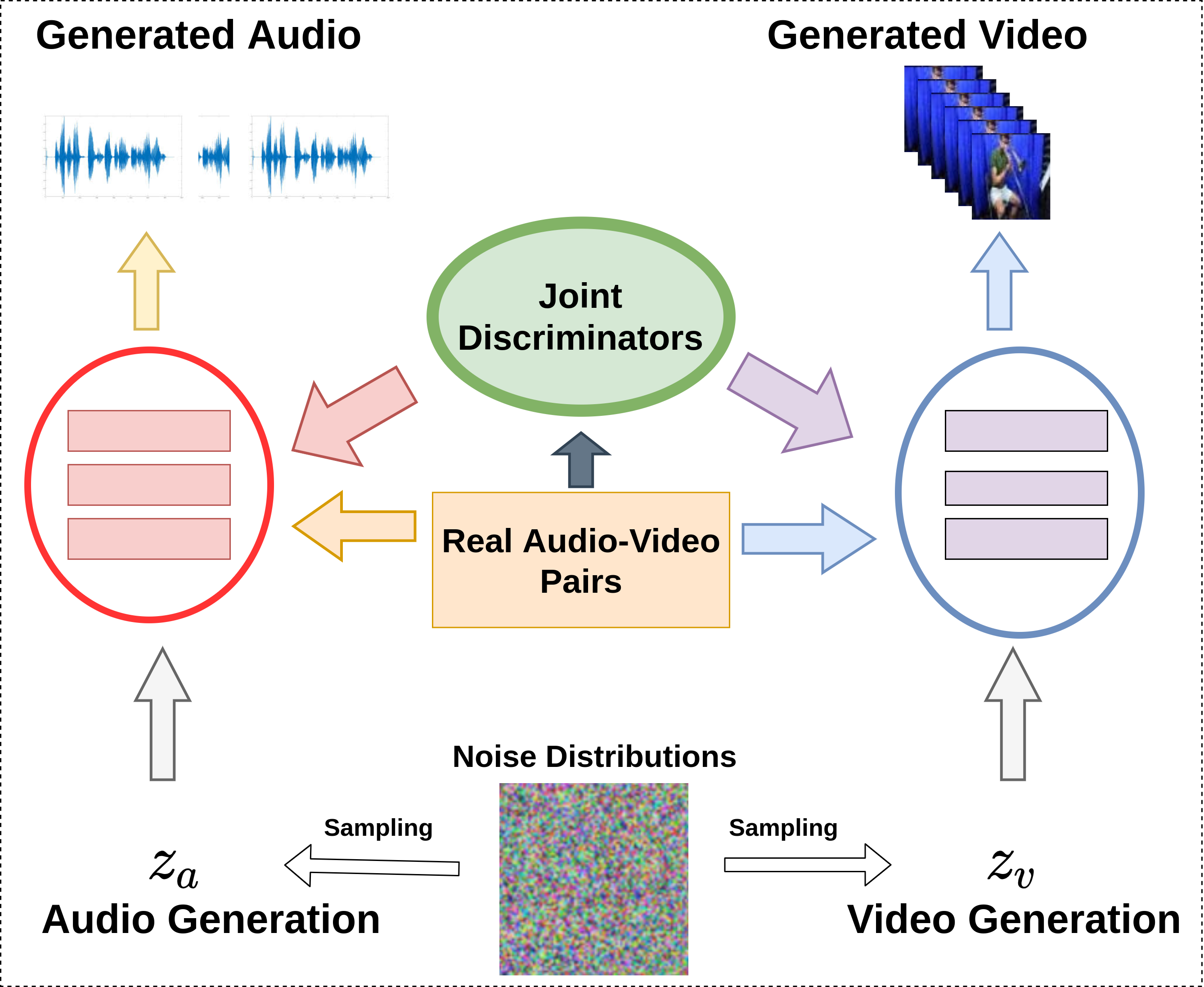
Collaborative Learning to Generate Audio-Video Jointly Vinod K Kurmi, Vipul Bajaj, Badri N. Patro, Venkatesh K Subramanian, Vinay P. Namboodiri, Preethi Jyothi IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2021.
There have been a number of techniques that have demonstrated the generation of multimedia data for one modality at a time using GANs, such as the ability to generate images, videos, and audio. However, so far, the task of multi-modal generation of data, specifically for audio and videos both, has not been sufficiently well-explored. Towards this, we propose a method that demonstrates that we are able to generate naturalistic samples of video and audio data by the joint correlated generation of audio and video modalities. The proposed method uses multiple discriminators to ensure that the audio, video, and the joint output are also indistinguishable from real-world samples. We present a dataset for this task and show that we are able to generate realistic samples. This method is validated using various standard metrics such as Inception Score, Frechet Inception Distance (FID) and through human evaluation.
@inproceedings{kurmi2021_avg,
Author = {Kurmi, Vinod Kumar and Bajaj, Vipul and Patro, Badri N and K S ,
Venaktesh and Namboodiri, Vinay and Jyothi, Preethi},
Title = {Collaborative Learning to Generate Audio-Video Jointly},
Booktitle = {ICASSP},
Year = {2021}
}
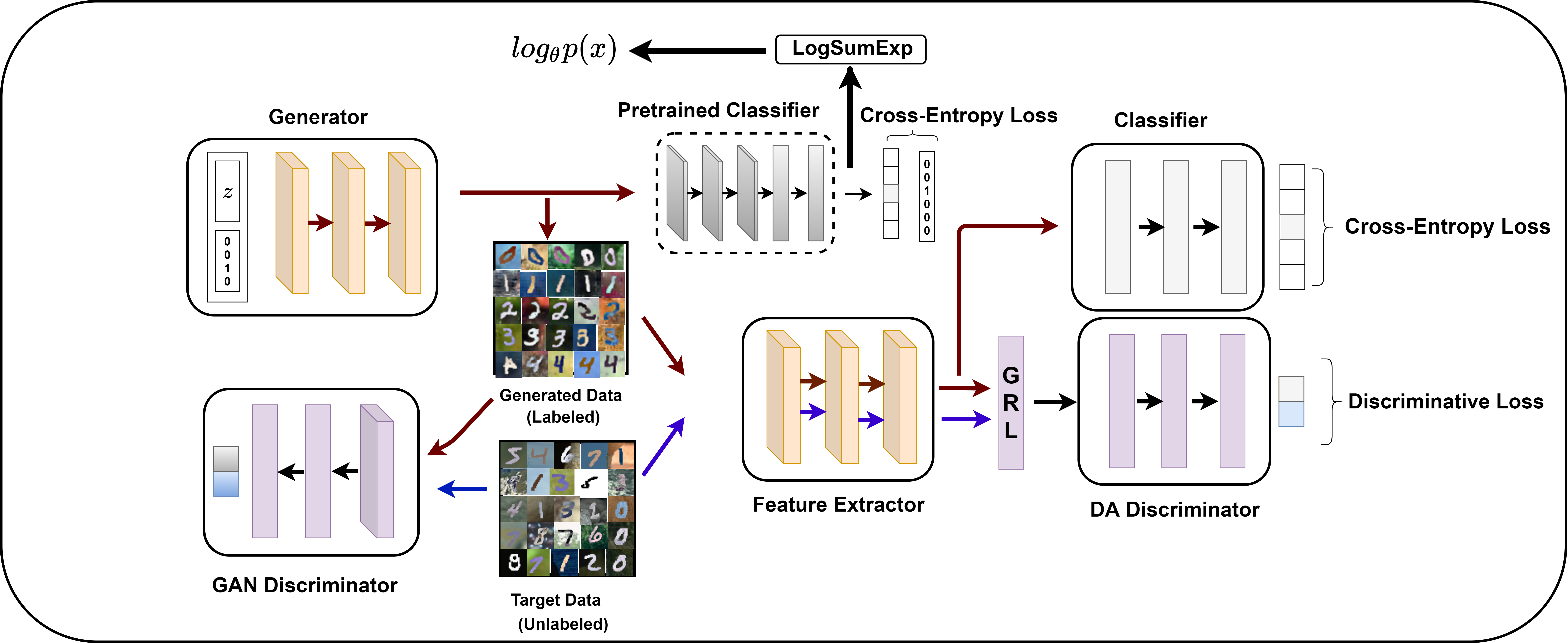
Unsupervised Domain adaptation methods solve the adaptation problem for an unlabeled target set, assuming that the source dataset is available with all labels. However, the availability of actual source samples is not always possible in practical cases. It could be due to memory constraints, privacy concerns, and challenges in sharing data. This practical scenario creates a bottleneck in the domain adaptation problem. This paper addresses this challenging scenario by proposing a domain adaptation technique that does not need any source data. Instead of the source data, we are only provided with a classifier that is trained on the source data. Our proposed approach is based on a generative framework, where the trained classifier is used for generating samples from the source classes. We learn the joint distribution of data by using the energy-based modeling of the trained classifier. At the same time, a new classifier is also adapted for the target domain. We perform various ablation analysis under different experimental setups and demonstrate that the proposed approach achieves better results than the baseline models in this extremely novel scenario.
@inproceedings{kurmi2021_sfda,
Author = {Kurmi, Vinod Kumar and K S ,
Venaktesh and Namboodiri, Vinay},
Title = {Domain Impression: A Source Data Free
Domain Adaptation Method},
Booktitle = {WACV},
Year = {2021}
}
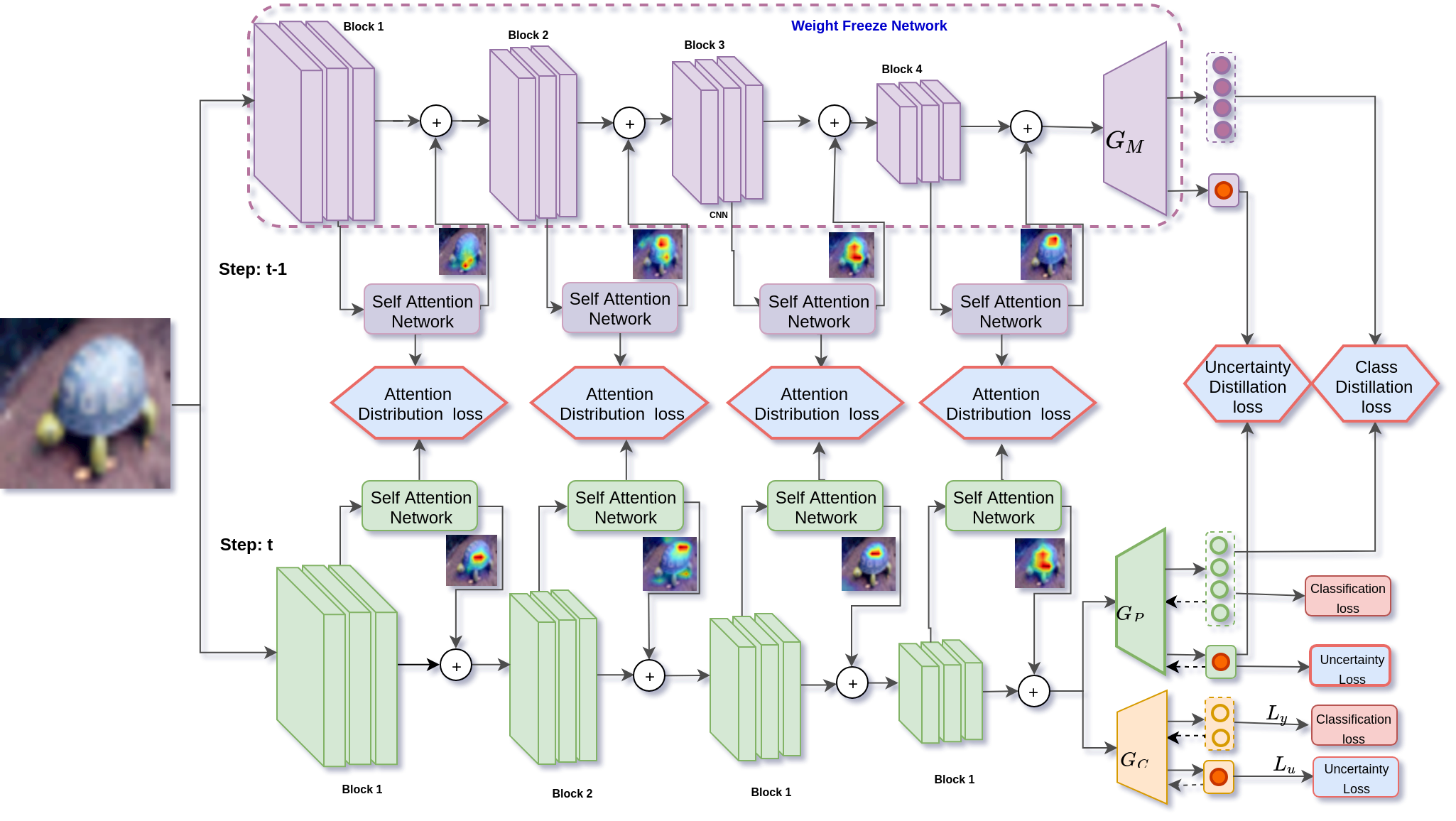
One of the major limitations of deep learning models is that they face catastrophic forgetting in an incremental learning scenario. There have been several approaches proposed to tackle the problem of incremental learning. Most of these methods are based on knowledge distillation and do not adequately utilize the information provided by older task models, such as uncertainty estimation in predictions. The predictive uncertainty provides the distributional information can be applied to mitigate catastrophic forgetting in a deep learning framework. In the proposed work, we consider a Bayesian formulation to obtain the data and model uncertainties. We also incorporate self-attention framework to address the incremental learning problem. We define distillation losses in terms of aleatoric uncertainty and self-attention. In the proposed work, we investigate different ablation analyses on these losses. Furthermore, we are able to obtain better results in terms of accuracy on standard benchmarks.
@inproceedings{kurmi2021_incre,
Author = {Kurmi, Vinod Kumar and Patro, Badri Narayana
and K S , Venaktesh and Namboodiri, Vinay},
Title = {Do not Forget to Attend to Uncertainty while
Mitigating Catastrophic Forgetting},
Booktitle = {WACV},
Year = {2021}
}
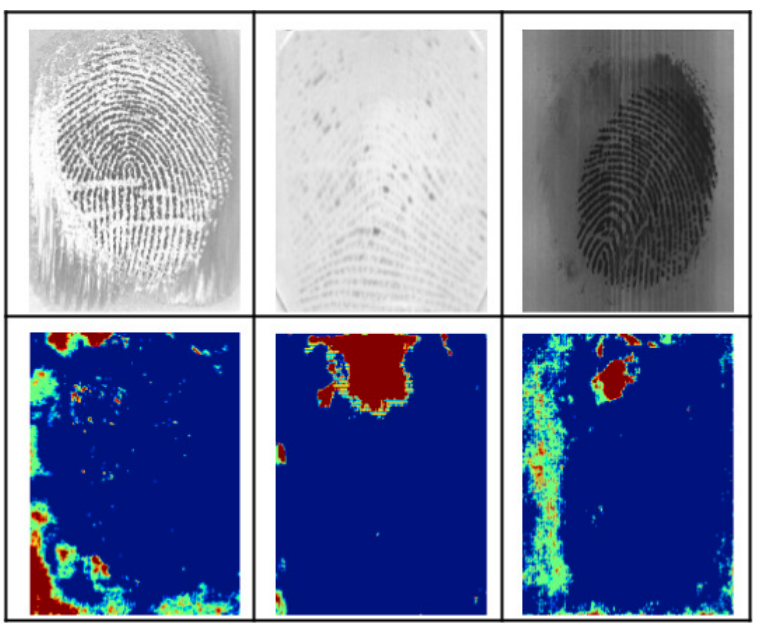
A fingerprint Region of Interest (ROI) segmentation module is one of the most crucial components in the fingerprint pre-processing pipeline. It separates the foreground fingerprint and background region due to which feature extraction and matching is restricted to ROI instead of entire fingerprint image. However, state-of-the-art segmentation algorithms act like a black box and do not indicate model confidence. In this direction, we propose an explainable fingerprint ROI segmentation model which indicates the pixels on which the model is uncertain. Towards this, we benchmark four state-of-the-art models for semantic segmentation on fingerprint ROI segmentation. Furthermore, we demonstrate the effectiveness of model uncertainty as an attention mechanism to improve the segmentation performance of the best performing model. Experiments on publicly available Fingerprint Verification Challenge (FVC) databases showcase the effectiveness of the proposed model.
@inproceedings{joshi021_w,
Author={Joshi, Indu and Kothari, Riya
and Utkarsh, Ayush and Kurmi, Vinod K
and Dantcheva,Antitza and Roy,
Sumantra Dutta and Kalra, Prem Kumar},
Title = {Explainable Fingerprint ROI Segmentation
Using Monte Carlo Dropout},
Booktitle = {IEEE Winter Conference on Applications
of Computer Vision Workshops (WACVW)},
Year = {2021}
}
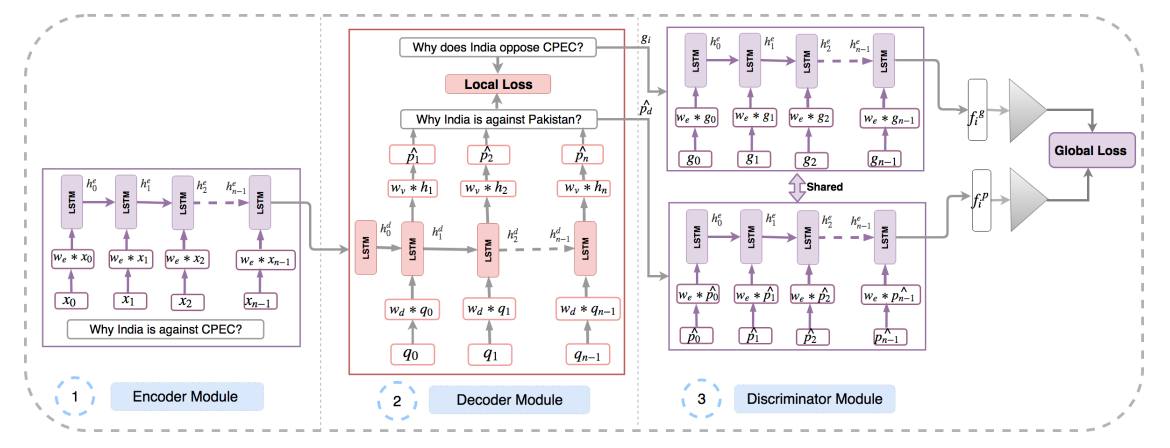
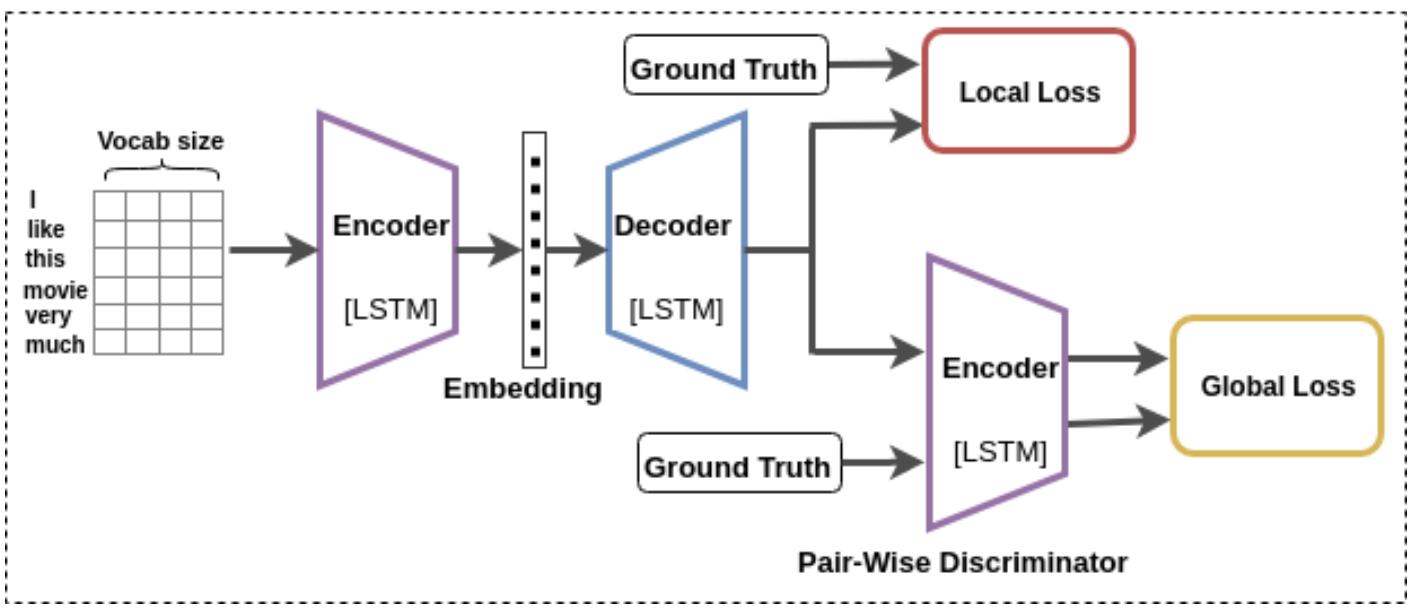
In this paper, we propose a method for obtaining sentence-level embeddings. While the problem of securing word-level embeddings is very well studied, we propose a novel method for obtaining sentence-level embeddings. This is obtained by a simple method in the context of solving the paraphrase generation task. If we use a sequential encoder-decoder model for generating paraphrase, we would like the generated paraphrase to be semantically close to the original sentence. One way to ensure this is by adding constraints for true paraphrase embeddings to be close and unrelated paraphrase candidate sentence embeddings to be far. This is ensured by using a sequential pair-wise discriminator that shares weights with the encoder that is trained with a suitable loss function. Our loss function penalizes paraphrase sentence embedding distances from being too large. This loss is used in combination with a sequential encoder-decoder network. We also validated our method by evaluating the obtained embeddings for a sentiment analysis task. The proposed method results in semantic embeddings and outperforms the state-of-the-art on the paraphrase generation and sentiment analysis task on standard datasets. These results are also shown to be statistically significant.
@inproceedings{patro2020Bayesian,
title={Revisiting Paraphrase Question Generator
using Pairwise Discriminator},
author={Patro, Badri Narayana and Chauhan, Dev
and Kurmi, Vinod Kumar and Namboodiri, Vinay},
booktitle={Neurocomputing},
year = {2020}
}
Generating natural questions from an image is a semantic task that requires using visual and language modality to learn multimodal representations. Images can have multiple visual and language contexts that are relevant for generating questions namely places, captions, and tags. In this paper, we propose the use of exemplars for obtaining the relevant context. We obtain this by using a Multimodal Differential Network to produce natural and engaging questions. The generated questions show a remarkable similarity to the natural questions as validated by a human study. Further, we observe that the proposed approach substantially improves over state-of-the-art benchmarks on the quantitative metrics (BLEU, METEOR, ROUGE, and CIDEr).
@inproceedings{patro2020Bayesian,
title={Deep Bayesian Network for Visual Question Generation},
author={Patro, Badri Narayana and Kumar, Sandeep
and Kurmi, Vinod Kumar and Namboodiri, Vinay},
booktitle={IEEE Winter Conference of Applications
on Computer Vision (WACV)},
year = {2020}
}
Domain adaptation is essential to enable wide usage of deep learning based networkstrained using large labeled datasets. Adversarial learning based techniques have showntheir utility towards solving this problem using a discriminator that ensures source andtarget distributions are close. However, here we suggest that rather than using a pointestimate, it would be useful if a distribution based discriminator could be used to bridgethis gap. This could be achieved using multiple classifiers or using traditional ensemblemethods. In contrast, we suggest that a Monte Carlo dropout based ensemble discrim-inator could suffice to obtain the distribution based discriminator. Specifically, we pro-pose a curriculum based dropout discriminator that gradually increases the variance ofthe sample based distribution and the corresponding reverse gradients are used to alignthe source and target feature representations. The detailed results and thorough ablationanalysis show that our model outperforms state-of-the-art results.
@article{kurmi2019curriculum,
title={Curriculum based Dropout Discriminator for Domain Adaptation},
author={Kurmi, Vinod Kumar and Bajaj, Vipul
and Subramanian, Venkatesh K and Namboodiri, Vinay P},
journal={BMVC},
year={2019} }
In this paper, we tackle a problem of Domain Adaptation. In a domain adaptation setting, there is provided a labeled set of examples in a source dataset with multiple classes being present and a target dataset that has no supervision. In this setting, we propose an adversarial discriminator based approach. While the approach based on adversarial discriminator has been previously proposed; in this paper, we present an informed adversarial discriminator. Our observation relies on the analysis that shows that if the discriminator has access to all the information available including the class structure present in the source dataset, then it can guide the transformation of features of the target set of classes to a more structured adapted space. Using this formulation, we obtain the state-of-the-art results for the standard evaluation on benchmark datasets. We further provide detailed analysis which shows that using all the labeled information results in an improved domain adaptation.
@InProceedings{kurmi2019looking,
author = {Kurmi, Vinod Kumar and
Namboodiri, Vinay P},
title = {Looking back at Labels:
A Class based Domain Adaptation
Technique},
booktitle = {International Joint
Conference on Neural Networks (IJCNN) },
month = {July},
year = {2019}
}
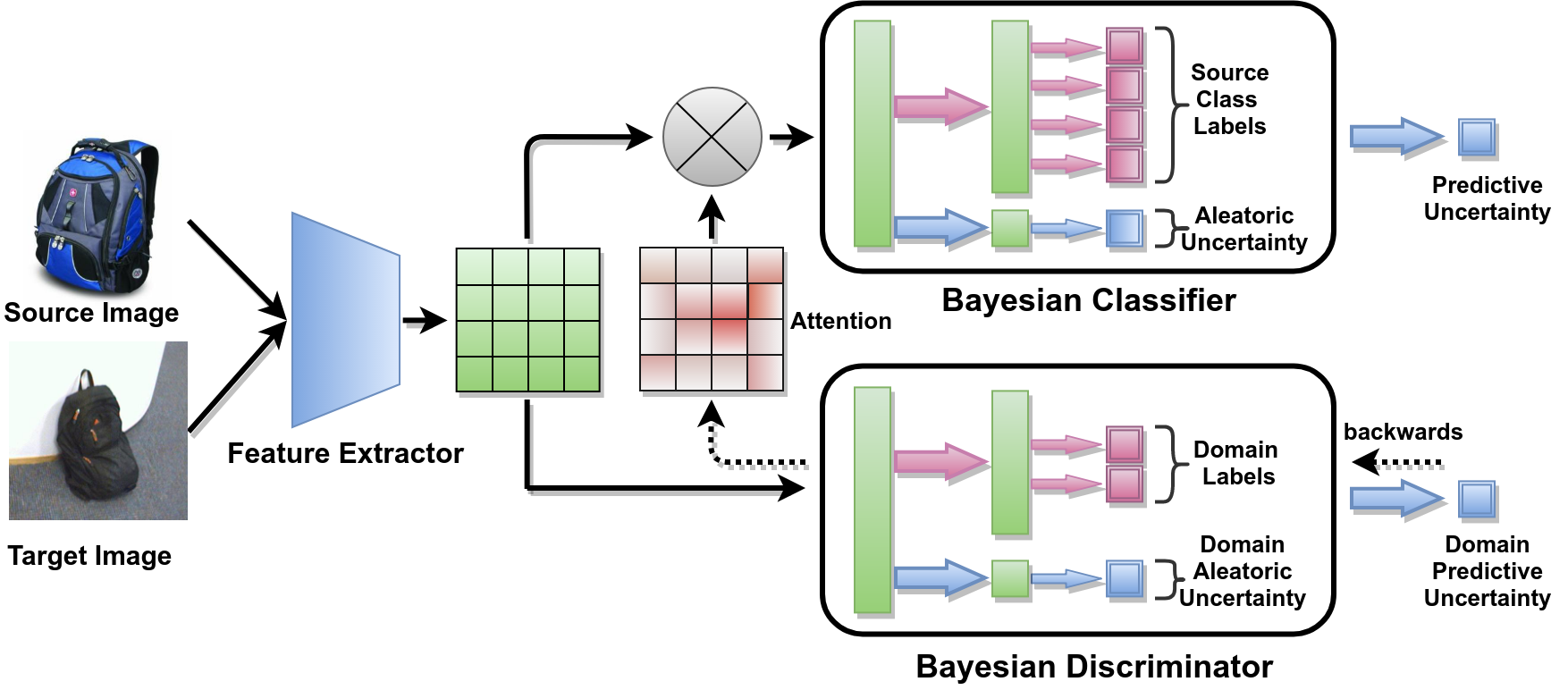
n this paper, we aim to solve for unsupervised domain adaptation of classifiers where we have access to label information for the source domain while these are not available for a target domain. While various methods have been proposed for solving these including adversarial discriminator based methods, most approaches have focused on the entire image based domain adaptation. In an image, there would be regions that can be adapted better, for instance, the foreground object may be similar in nature. To obtain such regions, we propose methods that consider the probabilistic certainty estimate of various regions and specific focus on these during classification for adaptation. We observe that just by incorporating the probabilistic certainty of the discriminator while training the classifier, we are able to obtain state of the art results on various datasets as compared against all the recent methods. We provide a thorough empirical analysis of the method by providing ablation analysis, statistical significance test, and visualization of the attention maps and t-SNE embeddings. These evaluations convincingly demonstrate the effectiveness of the proposed approach.
@InProceedings{Kurmi_2019_CVPR,
author = {Kumar Kurmi, Vinod and Kumar, Shanu
and Namboodiri, Vinay P.},
title = {Attending to Discriminative Certainty
for Domain Adaptation},
booktitle = {IEEE Computer Society Conference
on Computer Vision and Pattern Recognition(CVPR),},
month = {June},
year = {2019}
}
Generating natural questions from an image is a semantic task that requires using visual and language modality to learn multimodal representations. Images can have multiple visual and language contexts that are relevant for generating questions namely places, captions, and tags. In this paper, we propose the use of exemplars for obtaining the relevant context. We obtain this by using a Multimodal Differential Network to produce natural and engaging questions. The generated questions show a remarkable similarity to the natural questions as validated by a human study. Further, we observe that the proposed approach substantially improves over state-of-the-art benchmarks on the quantitative metrics (BLEU, METEOR, ROUGE, and CIDEr).
@inproceedings{patro2018multimodal,
title={Multimodal Differential Network
for Visual Question Generation},
author={Patro, Badri Narayana and Kumar,
Sandeep and Kurmi, Vinod Kumar and Namboodiri, Vinay},
booktitle={Proceedings of the 2018 Conference
on Empirical Methods in Natural Language Processing},
pages={4002--4012},
year={2018}
}
In this paper, we propose a method for obtaining sentence-level embeddings. While the problem of securing word-level embeddings is very well studied, we propose a novel method for obtaining sentence-level embeddings. This is obtained by a simple method in the context of solving the paraphrase generation task. If we use a sequential encoder-decoder model for generating paraphrase, we would like the generated paraphrase to be semantically close to the original sentence. One way to ensure this is by adding constraints for true paraphrase embeddings to be close and unrelated paraphrase candidate sentence embeddings to be far. This is ensured by using a sequential pair-wise discriminator that shares weights with the encoder that is trained with a suitable loss function. Our loss function penalizes paraphrase sentence embedding distances from being too large. This loss is used in combination with a sequential encoder-decoder network. We also validated our method by evaluating the obtained embeddings for a sentiment analysis task. The proposed method results in semantic embeddings and outperforms the state-of-the-art on the paraphrase generation and sentiment analysis task on standard datasets. These results are also shown to be statistically significant.
@inproceedings{patro2018learning,
title={Learning Semantic Sentence Embeddings
using Sequential Pair-wise Discriminator},
author={Patro, Badri Narayana and Kurmi,
Vinod Kumar and Kumar, Sandeep and
Namboodiri, Vinay},
booktitle={Proceedings of the 27th
International Conference on Computational
Linguistics},
pages={2715--2729},
year={2018}
}
Robust hand gesture recognition from 3D data Vinod K Kurmi, Garima Jain, Venkatesh K Subramanian International Conference in Central Europe on Computer Graphics, Visualization and Computer Vision (WSCG), 2015.
In this paper, we use the output of a 3D sensor (ex. Kinect from Microsoft) to capture depth images of humans making a set of predefined hand gestures in various body poses. Conventional approaches using Kinect data have been constrained by the limitation of the human detector middleware that requires close conformity to a standard near erect, legs apart, hands apart pose for the subject. Our approach also permits clutter and possible motion in the scene background, and to a limited extent, in the foreground as well. We make an important point in this work to emphasize that the recognition performance is considerably improved by a choice of hand gestures that accommodate the sensor’s specific limitations. These sensor limitations include low resolution in x and y as well as z. Hand gestures have been chosen (designed) for easy detection by seeking to detect a fingers apart, fingertip constellation with minimum computation. without, however compromising on issues of utility or ergonomy. It is shown that these gestures can be recognised in real time irrespective of visible band illumination levels, background motion, foreground clutter, user body pose, gesturing speeds and user distance. The last is of course limited by the sensor’s own range limitations. Our main contributions are the selection and design of gestures suitable for limited range, limited resolution 3D sensors and the novel method of depth slicing used to extract hand features from the background. This obviates the need for preliminary human detection and enables easy detection and highly reliable and fast (30 fps) gesture classification.
@article{kurmi2015robust,
title={Robust hand gesture recognition
from 3D data},
author={Kurmi, Vinod K and Jain, Garima
and Venkatesh, KS},
year={2015},
publisher={V{\'a}clav Skala-UNION Agency}
}











{kind=link}